
Python 操作pdf pdfplumber读取PDF写入Excel
1. Python 操作pdf(pdfplumber读取PDF写入Excel
1.1 安装pdfplumber模块库
安装pdfplumber:
pip install pdfplumber
pdfplumber.PDF类
pdfplumber.PDF类表示单个PDF ,并具有两个主要属性:
| 属性 | 说明 |
|---|---|
| pdf.metadata | 从PDF的Info中获取元数据键/值对字典。通常包括"CreationDate,“ModDater","Producer"等 |
| pdf.pages | 返回一个包含pdfplumber. Page实例的列表,每一一个实例代表PDF每一页的信息 |
pdfplumber.Page类
pdfplumber.Page类常用属性
| 属性page_ number | 说明 |
|---|---|
| .page_ number | 顺序页码,从1第一页开始,从第二页开始2 ,依此类推 |
| .width | 页面的宽度 |
| .height | 页面的高度 |
| .objects/ . chars/ .lines/ .rects/ . curves/ .figures/ . images | 这些属性中的每一个都是一 个列表, 每个列表包含一个字典 ,用于嵌入页面上的每个此类对象,有关详细信息,请参阅下面的“对象”。 |
常用方法:
| 方法名 | 说明 |
|---|---|
| .extract_ text( ) | 用来提页面中的文本,将页面的所有字符对象整理为的那个字符串 |
| .extract_ words( ) | 返回的是所有的单词及其相关信息 |
| . extract_ tables() | 提取页面的表格 |
| .to_ _image() | 用于可视化调试时,返回Pagelmage类的一个实例 |
| .close() | 默认情况下, Page对象缓存其布局和对象信息,以避免重新处理它, 但是在解析大型PDF时,这些缓存的属性可能需要大量内存。您可以使用此方法刷新缓存并释放内存。 |
1.2 常用操作
PDF是Portable Document Format的缩写,这类文件通常使用.pdf作为其扩展名。在日常开发工作中,最容易遇到的就是从PDF中读取文本内容以及用已有的内容生成PDF文档这两个任务。
- 1.读取pdf文档信息
- 2.输出总页数
- 3.读取第一页宽度、高度等信息
- 4.读取文本第一页
加载pdf:
- pdfplumber.open( "路径/文件名. pdf".pas sword="test "laparams={ "line_ _overlap'”0.7 })
- password : 要加载受密码保护的PDF ,请传递password关键字参数
- laparams :要将布局分析参数设置为pdfminer. six的布局引擎,请传递laparams关键字参数
1.2.1 Python读取pdf文件案例
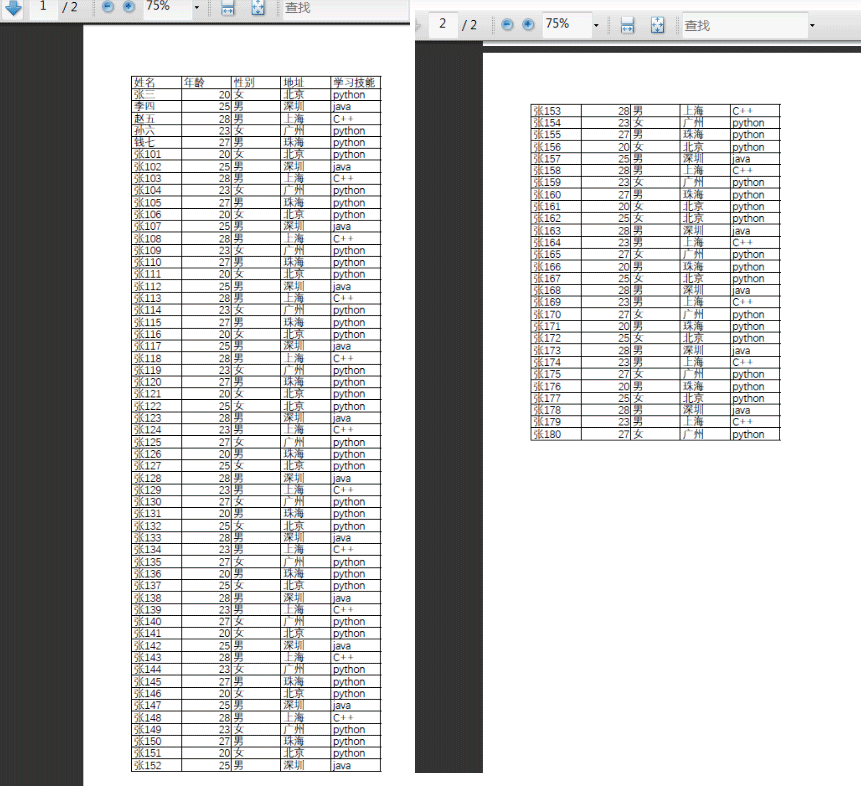
pdf文件如下:
1.2.2 Python读取pdf文件代码
import pdfplumber
# 加载pdf
path = "C:/Users/Administrator/Desktop/test08/test11 - 多页.pdf"
with pdfplumber.open(path) as pdf:
print(pdf)
print(type(pdf))
# 读取pdf文档信息
print("pdf文档信息:", pdf.metadata)
# 输出总页数
print("pdf文档总页数:", len(pdf.pages))
# 1.读取第一页宽度、高度等信息
first_page = pdf.pages[0] # pdfplumber.Page对象第一页
# 查看页码
print('pdf页码:', first_page.page_number)
# 查看页宽
print('pdf页宽:', first_page.width)
# 查看页高
print('pdf页高:', first_page.height)
# 2.读取文本第一页
first_page = pdf.pages[0] # pdfplumber.Page对象第一页
text = first_page.extract_text()
print(text)执行结果:
"D:\Program Files1\Python\python.exe" D:/Pycharm-work/pythonTest/打卡/0811读取pdf.py
<pdfplumber.pdf.PDF object at 0x0000000002846278>
<class 'pdfplumber.pdf.PDF'>
pdf文档信息: {'Author': '', 'Comments': '', 'Company': '', 'CreationDate': "D:20220812102327+02'23'", 'Creator': 'WPS 表格', 'Keywords': '', 'ModDate': "D:20220812102327+02'23'", 'Producer': '', 'SourceModified': "D:20220812102327+02'23'", 'Subject': '', 'Title': '', 'Trapped': 'False'}
pdf文档总页数: 2
pdf页码: 1
pdf页宽: 595.25
pdf页高: 841.85
姓名 年龄 性别 地址 学习技能
张三 20 女 北京 python
李四 25 男 深圳 java
赵五 28 男 上海 C++
孙六 23 女 广州 python
钱七 27 男 珠海 python
张101 20 女 北京 python
.......
.......
张150 27 男 珠海 python
张151 20 女 北京 python
张152 25 男 深圳 javaProcess finished with exit code 0
1.2.3 Python读取pdf文件存入Excel代码
import pdfplumber
import xlwt
# 加载pdf
path = "C:/Users/Administrator/Desktop/test08/test11 - 多页.pdf"
with pdfplumber.open(path) as pdf:
page_1 = pdf.pages[0] # pdf第一页
table_1 = page_1.extract_table() # 读取表格数据
print(table_1)
# 1.创建Excel对象
workbook = xlwt.Workbook(encoding='utf8')
# 2.新建sheet表
worksheet = workbook.add_sheet('Sheet1')
# 3.自定义列名
clo1 = table_1[0]
# 4.将列表元组clo1写入sheet表单中的第一行
for i in range(0, len(clo1)):
worksheet.write(0, i, clo1[i])
# 5.将数据写进sheet表单中
for i in range(0, len(table_1[1:])):
data = table_1[1:][i]
for j in range(0, len(clo1)):
worksheet.write(i + 1, j, data[j])
# 保存Excel文件分两种
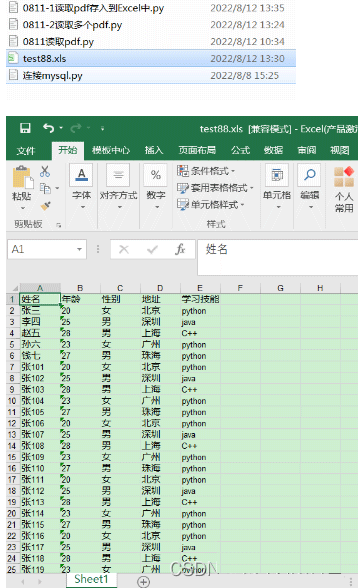
workbook.save('test88.xls')执行结果:
到此这篇关于Python 操作pdf pdfplumber读取PDF写入Excel的文章就介绍到这了,更多相关Python 操作pdf内容请搜索以前的文章或继续浏览下面的相关文章希望大家以后多多支持!
若文章对您有帮助,帮忙点个赞!
(微信扫码即可登录,无需注册)