
解决Mybatis 大数据量的批量insert问题
前言
通过Mybatis做7000+数据量的批量插入的时候报错了,error log如下:
,
('G61010352',
'610103199208291214',
'学生52',
'G61010350',
'610103199109920192',
'学生50',
'07',
'01',
'0104',
' ',
,
' ',
' ',
current_timestamp,
current_timestamp
)
被中止,呼叫 getNextException 以取得原因。
at org.postgresql.jdbc2.AbstractJdbc2Statement$BatchResultHandler.handleError(AbstractJdbc2Statement.java:2743) at org.postgresql.core.v3.QueryExecutorImpl.execute(QueryExecutorImpl.java:411) at org.postgresql.jdbc2.AbstractJdbc2Statement.executeBatch(AbstractJdbc2Statement.java:2892) at com.alibaba.druid.filter.FilterChainImpl.statement_executeBatch(FilterChainImpl.java:2596) at com.alibaba.druid.wall.WallFilter.statement_executeBatch(WallFilter.java:473) at com.alibaba.druid.filter.FilterChainImpl.statement_executeBatch(FilterChainImpl.java:2594) at com.alibaba.druid.filter.FilterAdapter.statement_executeBatch(FilterAdapter.java:2474) at com.alibaba.druid.filter.FilterEventAdapter.statement_executeBatch(FilterEventAdapter.java:279) at com.alibaba.druid.filter.FilterChainImpl.statement_executeBatch(FilterChainImpl.java:2594) at com.alibaba.druid.proxy.jdbc.StatementProxyImpl.executeBatch(StatementProxyImpl.java:192) at com.alibaba.druid.pool.DruidPooledPreparedStatement.executeBatch(DruidPooledPreparedStatement.java:559) at org.apache.ibatis.executor.BatchExecutor.doFlushStatements(BatchExecutor.java:108) at org.apache.ibatis.executor.BaseExecutor.flushStatements(BaseExecutor.java:127) at org.apache.ibatis.executor.BaseExecutor.flushStatements(BaseExecutor.java:120) at org.apache.ibatis.executor.BaseExecutor.commit(BaseExecutor.java:235) at org.apache.ibatis.executor.CachingExecutor.commit(CachingExecutor.java:112) at org.apache.ibatis.session.defaults.DefaultSqlSession.commit(DefaultSqlSession.java:196) at org.mybatis.spring.SqlSessionTemplate$SqlSessionInterceptor.invoke(SqlSessionTemplate.java:390) ... 39 more
可以看到这种异常无法捕捉,仅能看到异常指向了druid和ibatis的原码处,初步猜测是由于默认的SqlSession无法支持这个数量级的批量操作,下面就结合源码和官方文档具体看一看。
源码分析
项目使用的是Spring+Mybatis,在Dao层是通过Spring提供的SqlSessionTemplate来获取SqlSession的:
@Resource(name = "sqlSessionTemplate")
private SqlSessionTemplate sqlSessionTemplate;
public SqlSessionTemplate getSqlSessionTemplate()
{
return sqlSessionTemplate;
}
为了验证,接下看一下它是如何提供SqlSesion的,打开SqlSessionTemplate的源码,看一下它的构造方法:
/**
* Constructs a Spring managed SqlSession with the {@code SqlSessionFactory}
* provided as an argument.
*
* @param sqlSessionFactory
*/
public SqlSessionTemplate(SqlSessionFactory sqlSessionFactory) {
this(sqlSessionFactory, sqlSessionFactory.getConfiguration().getDefaultExecutorType());
}
接下来再点开getDefaultExecutorType这个方法:
public ExecutorType getDefaultExecutorType() {
return defaultExecutorType;
}
可以看到它直接返回了类中的全局变量defaultExecutorType,我们再在类的头部寻找一下这个变量:
protected ExecutorType defaultExecutorType = ExecutorType.SIMPLE;
找到了,Spring为我们提供的默认执行器类型为Simple,它的类型一共有三种:
/**
* @author Clinton Begin
*/
public enum ExecutorType {
SIMPLE, REUSE, BATCH
}
仔细观察一下,发现有3个枚举类型,其中有一个BATCH是否和批量操作有关呢?我们看一下mybatis官方文档中对这三个值的描述:
- ExecutorType.SIMPLE: 这个执行器类型不做特殊的事情。它为每个语句的执行创建一个新的预处理语句。
- ExecutorType.REUSE: 这个执行器类型会复用预处理语句。
- ExecutorType.BATCH:这个执行器会批量执行所有更新语句,如果 SELECT 在它们中间执行还会标定它们是 必须的,来保证一个简单并易于理解的行为。
可以看到我的使用的SIMPLE会为每个语句创建一个新的预处理语句,也就是创建一个PreparedStatement对象,即便我们使用druid连接池进行处理,依然是每次都会向池中put一次并加入druid的cache中。这个效率可想而知,所以那个异常也有可能是insert timeout导致等待时间超过数据库驱动的最大等待值。
好了,已解决问题为主,根据分析我们选择通过BATCH的方式来创建SqlSession,官方也提供了一系列重载方法:
SqlSession openSession() SqlSession openSession(boolean autoCommit) SqlSession openSession(Connection connection) SqlSession openSession(TransactionIsolationLevel level) SqlSession openSession(ExecutorType execType,TransactionIsolationLevel level) SqlSession openSession(ExecutorType execType) SqlSession openSession(ExecutorType execType, boolean autoCommit) SqlSession openSession(ExecutorType execType, Connection connection)
可以观察到主要有四种参数类型,分别是
- Connection connection - ExecutorType execType - TransactionIsolationLevel level - boolean autoCommit
官方文档中对这些参数也有详细的解释:
SqlSessionFactory 有六个方法可以用来创建 SqlSession 实例。通常来说,如何决定是你 选择下面这些方法时:
Transaction (事务): 你想为 session 使用事务或者使用自动提交(通常意味着很多 数据库和/或 JDBC 驱动没有事务)?
Connection (连接): 你想 MyBatis 获得来自配置的数据源的连接还是提供你自己
Execution (执行): 你想 MyBatis 复用预处理语句和/或批量更新语句(包括插入和 删除)?
所以根据需求选择即可,由于我们要做的事情是批量insert,所以我们选择SqlSession openSession(ExecutorType execType, boolean autoCommit)
顺带一提关于TransactionIsolationLevel也就是我们经常提起的事务隔离级别,官方文档中也介绍的很到位:
MyBatis 为事务隔离级别调用使用一个 Java 枚举包装器, 称为 TransactionIsolationLevel, 否则它们按预期的方式来工作,并有 JDBC 支持的 5 级
NONE, READ_UNCOMMITTED READ_COMMITTED, REPEATABLE_READ, SERIALIZA BLE)
解决问题
回归正题,初步找到了问题原因,那我们换一中SqlSession的获取方式再试试看。
testing… 2minutes later…
不幸的是,依旧报相同的错误,看来不仅仅是ExecutorType的问题,那会不会是一次commit的数据量过大导致响应时间过长呢?上面我也提到了这种可能性,那么就再分批次处理试试,也就是说,在同一事务范围内,分批commit insert batch。具体看一下Dao层的代码实现:
@Override
public boolean insertCrossEvaluation(List<CrossEvaluation> members)
throws Exception {
// TODO Auto-generated method stub
int result = 1;
SqlSession batchSqlSession = null;
try {
batchSqlSession = this.getSqlSessionTemplate()
.getSqlSessionFactory()
.openSession(ExecutorType.BATCH, false);// 获取批量方式的sqlsession
int batchCount = 1000;// 每批commit的个数
int batchLastIndex = batchCount;// 每批最后一个的下标
for (int index = 0; index < members.size();) {
if (batchLastIndex >= members.size()) {
batchLastIndex = members.size();
result = result * batchSqlSession.insert("MutualEvaluationMapper.insertCrossEvaluation",members.subList(index, batchLastIndex));
batchSqlSession.commit();
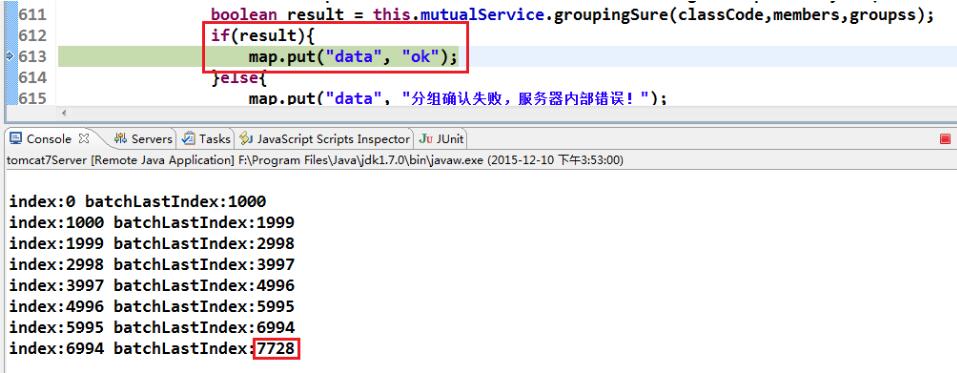
System.out.println("index:" + index+ " batchLastIndex:" + batchLastIndex);
break;// 数据插入完毕,退出循环
} else {
result = result * batchSqlSession.insert("MutualEvaluationMapper.insertCrossEvaluation",members.subList(index, batchLastIndex));
batchSqlSession.commit();
System.out.println("index:" + index+ " batchLastIndex:" + batchLastIndex);
index = batchLastIndex;// 设置下一批下标
batchLastIndex = index + (batchCount - 1);
}
}
batchSqlSession.commit();
}
finally {
batchSqlSession.close();
}
return Tools.getBoolean(result);
}
再次测试,程序没有报异常,总共7728条数据 insert的时间大约为10s左右,如下图所示,
总结
简单记录一下Mybatis批量insert大数据量数据的解决方案,仅供参考,Tne End。
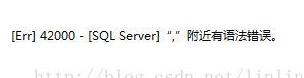
补充:mybatis批量插入报错:','附近有错误
mybatis批量插入的时候报错,报错信息‘,'附近有错误
mapper.xml的写法为
<insert id="insertByBatch">
INSERT INTO USER_LOG (USER_ID, OP_TYPE, CONTENT, IP, OP_ID, OP_TIME) VALUES
<foreach collection="userIds" item="userId" open="(" close=")" separator=",">
(#{rateId}, #{opType}, #{content}, #{ipStr}, #{userId}, #{opTime},
</foreach>
</insert>
打印的sql语句
INSERT INTO USER_LOG (USER_ID, OP_TYPE, CONTENT, IP, OP_ID, OP_TIME) VALUES ( (?, ?, ?, ?, ?, ?) , (?, ?, ?, ?, ?, ?) )
调试的时候还是把sql复制到navicate中进行检查,就报了上面的错。这个错看起来毫无头绪,然后就自己重新写insert语句,发现正确的语句应该为
INSERT INTO USER_LOG (USER_ID, OP_TYPE, CONTENT, IP, OP_ID, OP_TIME) VALUES (?, ?, ?, ?, ?, ?) , (?, ?, ?, ?, ?, ?)
比之前的sql少了外面的括号,此时运行成功,所以mapper.xml中应该把opern=”(” close=”)”删除即可。
多说一句,批量插入的时候也可以把要插入的数据组装成List<实体>,这样就不用传这么多的参数了。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持。如有错误或未考虑完全的地方,望不吝赐教。
若文章对您有帮助,帮忙点个赞!
(微信扫码即可登录,无需注册)