
Python利用 utf-8-sig 编码格式解决写入 csv 文件乱码问题
先举个例子,分别以不指定编码、指定编码为 utf-8、指定编码为 utf-8-sig 三种方式来做比较,再将写入 csv 文件和 txt 文件来做个对比
一、不指定编码方式,直接存入 csv 文件
import csv
with open('test.csv', 'w') as fp:
writer = csv.writer(fp)
writer.writerow(['汉语', '俄语', '韩语', '日语', '英语'])
writer.writerow(['爱你', 'люблю тебя', '사랑해요', '愛しています', 'love you'])
此时运行程序会报以下错误:
UnicodeEncodeError: 'gbk' codec can't encode character '\uc0ac' in position 14: illegal multibyte sequence
二、指定编码为 utf-8,再存入 csv 文件
接下来尝试将内容以 utf-8 编码方式存入 test.csv 文件中,可以看到除了英文,其他的全都是乱码:
import csv
with open('test.csv', 'w', encoding='utf-8') as fp:
writer = csv.writer(fp)
writer.writerow(['汉语', '俄语', '韩语', '日语', '英语'])
writer.writerow(['爱你', 'люблю тебя', '사랑해요', '愛しています', 'love you'])
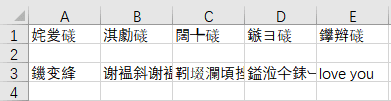
三、指定编码为 utf-8-sig,再存入 csv 文件
当将编码方式换成 utf-8-sig 之后,显示为正常:
import csv
with open('test.csv', 'w', encoding='utf-8-sig') as fp:
writer = csv.writer(fp)
writer.writerow(['汉语', '俄语', '韩语', '日语', '英语'])
writer.writerow(['爱你', 'люблю тебя', '사랑해요', '愛しています', 'love you'])
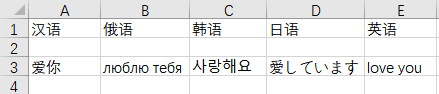
四、不指定编码方式,直接存入 txt 文件
with open('test.txt','w') as fp:
fp.write('爱你, люблю тебя, 사랑해요, 愛しています, love you')
和存入 csv 文件一样,也会报以下错误:
UnicodeEncodeError: 'gbk' codec can't encode character '\uc0ac' in position 16: illegal multibyte sequence
五、指定编码为 utf-8 / utf-8-sig,再存入 txt 文件
以 utf-8 或者 utf-8-sig 编码方式存入 test.txt 文件中,内容都是完全正常的:
ith open('test.txt','w', encoding='utf-8') as fp:
fp.write('爱你, люблю тебя, 사랑해요, 愛しています, love you')
with open('test.txt','w', encoding='utf-8-sig') as fp:
fp.write('爱你, люблю тебя, 사랑해요, 愛しています, love you')

utf-8 与 utf-8-sig 有什么区别?
-
utf-8以字节为编码单元,它的字节顺序在所有系统中都是一样的,没有字节序问题,也因此它实际上并不需要 BOM; -
uft-8-sig中 sig 全拼为 signature,即带有签名的 utf-8(UTF-8 with BOM); -
BOM全称 ByteOrder Mark,字节顺序标记,出现在文本文件头部,Unicode编码标准中用于标识文件是采用哪种格式的编码。
为什么写入 csv 文件要用 utf-8-sig 编码?
- Excel 在读取 csv 文件的时候是通过读取文件头上的 BOM 来识别编码的,如果文件头无 BOM 信息,则默认按照 Unicode 编码读取。
- 当我们使用 utf-8 编码来生成 csv 文件的时候,并没有生成 BOM 信息,Excel 就会自动按照 Unicode 编码读取,就会出现乱码问题了。
为什么写入 txt 文件要用 utf-8 编码?
在写入 txt 文件时,Windows 会默认转码成 gbk,遇到某些 gbk 不支持的字符就会报错,在打开文件时就声明编码方式为 utf-8 就能避免这个错误。
知识点扩展:
utf-8和utf-8-sig的区别
前言:在写入csv文件中,出现了乱码的问题。
解决:utf-8 改为utf-8-sig
区别如下:
1、”utf-8“ 是以字节为编码单元,它的字节顺序在所有系统中都是一样的,没有字节序问题,因此它不需要BOM,所以当用"utf-8"编码方式读取带有BOM的文件时,它会把BOM当做是文件内容来处理, 也就会发生类似上边的错误.
2、“uft-8-sig"中sig全拼为 signature 也就是"带有签名的utf-8”, 因此"utf-8-sig"读取带有BOM的"utf-8文件时"会把BOM单独处理,与文本内容隔离开,也是我们期望的结果.
总结
以上所述是小编给大家介绍的Python利用 utf-8-sig 编码格式解决写入 csv 文件乱码问题,希望对大家有所帮助,也非常感谢大家对网站的支持!
若文章对您有帮助,帮忙点个赞!
(微信扫码即可登录,无需注册)