
python多进程中的生产者和消费者模型详解
Python生产者消费者模型
一、消费模式
生产者消费者模式 是Controlnet网络中特有的一种传输数据的模式。用于两个CPU之间传输数据,即使是不同类型同一厂家的CPU也可以通过设置来使用。
二、传输原理
- 类似与点对点传送,又略有不同,一个生产者可以对应N个消费者,但是一个消费者只能对应一个生产者;
- 每个生产者消费者对应一个地址,占一个网络节点,属于预定性数据,在网络中优先级最高;
- 此模式如果在网络中设置过多会影响网络传输速度,一般用在传输比较重要的信息上,比如设备的启动、停止、故障、急停等等;
- 在Controlnet网络中节点数是有限制的,最高节点数为99。
- 如果两个控制器之前建立了多个生产者消费者的连接,只要一个失败,则所有的均失败,将数据整合到用户自定义结构或数组中 ,两个控制器中只保留一个连接。
- 生产者消费者信息可以通过以太网和Controlnet传输,但是同时只能通过一种途径传输;
- 建立标签时必须建立在全局变量里面,不能建立在局部变量里标签的大小不能超过500B;
- 如果生产者几个数据传输到到同一个控制器的的几个消费者中,将几个数据合并在一个用户自定义标签中,可以减少连接数,但合并后的数据将会会用相同的RPI。
- 生产者消费者标签只能用DINT和REAL,或它们的数组,或用户自定义结构数据,因为对外操作数据必须是32位的,如果有SINT和INT的数据要传输,必须将它们组合在用户自定义结构中传送,生产者和消费者的标签数据格式必须一致,才能确保数据的准确性,如果数据打包后超过了 32位,那么生产者和消费者双方必须使用一个复制缓冲指令,以获得数据的同步,例如Control Logix中的CPS指令。
- 如果生产者要发送的32位数据,与非Control Logix的对方设备的数据结构不匹配,例如对方是16位的数据,为避免偏差,改为用户自定义结构。
- 消费者的 RPI必须大于等于网络刷新时间NUT,如果几个消费者请求同一个生产者,则会以最小最快的RPI为准。
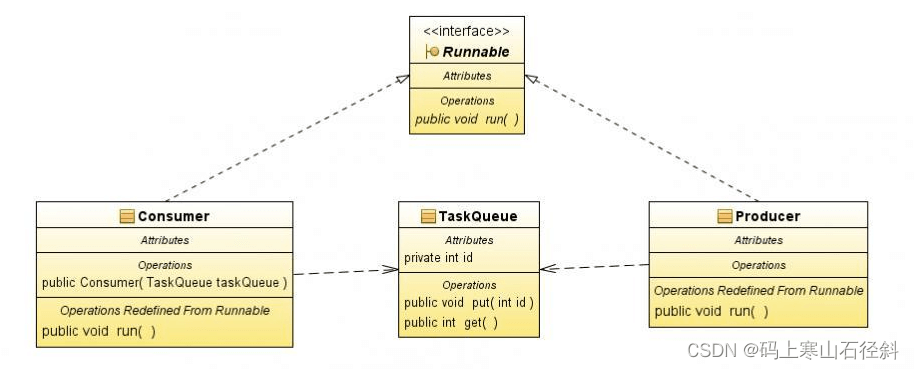
三、实现方式
方法一:
import threading,queue,time
# 创建一个队列,队列最大长度为2
q = queue.Queue(maxsize=2)
def product():
while True:
# 生产者往队列塞数据
q.put('money')
print('生产了money, 生产时间:', time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()))
def consume():
while True:
time.sleep(0.5)
# 消费者取出数据
data = q.get()
print('消费了%s, 消费时间%s' % (data, time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())))
t = threading.Thread(target=product)
t1 = threading.Thread(target=consume)
t.start()
t1.start()缺点:
实现了多少个消费者consumer进程,就需要在最后往队列中添加多少个None标识,方便生产完毕结束消费者consumer进程。否则,p.get() 不到任务会阻塞子进程,因为while循环,直到队列q中有新的任务加进来,才会再次执行。而我们的生产者只能生产这么多东西,所以相当于程序卡死。
方法二:
from multiprocessing import JoinableQueue,Process
import time
def producer(q):
for i in range(4):
time.sleep(0.5)
f = '生产者:已经生产'
q.put(f)
print(f)
q.join() # 一直阻塞,等待消耗完所有的数据后才释放
def consumer(name, q):
while True:
food = q.get()
print('\033[消费者:消费了%s\033' % name)
time.sleep(0.5)
q.task_done() # 每次消耗减1
if __name__ == '__main__':
q = JoinableQueue() # 创建队列
# 模拟生产者队列
p1 = Process(target=producer, args=(q, ))
p1.start()
# 模拟消费者队列
c1 = Process(target=consumer, args=('money', q))
c1.daemon = True # 守护进程:主进程结束,子进程也会结束
c1.start()
p1.join() # 阻塞主进程,等到p1子进程结束才往下执行
优点:参考地址
- 使用JoinableQueue组件,是因为JoinableQueue中有两个方法:task_done()和join() 。首先说join()和Process中的join()的效果类似,都是阻塞当前进程,防止当前进程结束。但是JoinableQueue的join()是和task_down()配合使用的。
- Process中的join()是等到子进程中的代码执行完毕,就会执行主进程join()下面的代码。而JoinableQueue中的join()是等到队列中的任务数量为0的时候才会执行q.join()下面的代码,否则会一直阻塞。
- task_down()方法是每获取一次队列中的任务,就需要执行一次。直到队列中的任务数为0的时候,就会执行JoinableQueue的join()后面的方法了。所以生产者生产完所有的数据后,会一直阻塞着。不让p1和p2进程结束。等到消费者get()一次数据,就会执行一次task_down()方法,从而队列中的任务数量减1,当数量为0后,执行JoinableQueue的join()后面代码,从而p1和p2进程结束。
- 因为p1和p2添加了join()方法,所以当子进程中的consumer方法执行完后,才会往下执行。从而主进程结束。因为这里把消费者进程c1和c2 设置成了守护进程,主进程结束的同时,c1和c2 进程也会随之结束,进程都结束了。所以消费者consumer方法也会结束。
到此这篇关于python多进程中的生产者和消费者模型详解的文章就介绍到这了,更多相关python生产者和消费者模型内容请搜索以前的文章或继续浏览下面的相关文章希望大家以后多多支持!
若文章对您有帮助,帮忙点个赞!
(微信扫码即可登录,无需注册)