
如何优化MySQL的order by查询?
如何优化MySQL的order by查询?
order by 查询语句使用也是非常频繁,有时候数据量大了会发现排序查询很慢,本文就介绍一下 MySQL 是如何进行排序的,以及如何利用其原理来优化 order by 语句。
建立一张表:
CREATE TABLE `cc4` ( `id` INT(11) NOT NULL, `user_name` VARCHAR(16) NOT NULL, `job` VARCHAR(16) NOT NULL, `company` VARCHAR(16) DEFAULT NULL, PRIMARY KEY (`id`), KEY `company_index` (`company`) ) ENGINE=INNODB;
建完表之后,再创建一个脚本,在脚本中插入 2000 条数据到前面建好的表cc4 中:
DROP PROCEDURE IF EXISTS cc4_data;
DELIMITER ;;
CREATE PROCEDURE cc4_data()
BEGIN
DECLARE i INT;
DECLARE company VARCHAR(128);
SET i=1;
WHILE(i<=2000) DO
IF i%6 = 0
THEN SET company= '证券';
ELSEIF i%6 = 1
THEN SET company= '银行';
ELSEIF i%6 = 2
THEN SET company= '保险';
ELSEIF i%6 = 3
THEN SET company= '科技';
ELSEIF i%6 = 4
THEN SET company= '金融';
ELSE
SET company ='传统';
END IF;
INSERT INTO cc4 VALUES(i, CONCAT('孤狼',i), CONCAT('程序员',i),company);
SET i=i+1;
END WHILE;
END;;
DELIMITER ;
CALL cc4_data();
这时候我们如果想要对某一家公司里面的人按照名字进行排序,一般会这么写:
SELECT user_name,job,company FROM cc4 WHERE company='科技' ORDER BY user_name LIMIT 1000;
这是一条非常简单且常见的 sql 语句,但是就是这么简单的一条 sql,它到底是如何被执行的呢?
全字段排序法
首先我们对上面的语句执行 explain 语句,看看是怎么执行的:
explain SELECT user_name,job,company FROM cc4 WHERE company='科技' ORDER BY user_name LIMIT 1000;

可以看到,在最后一列 Extra 中显示 Using filesort,也就是说用到了文件排序,这个文件排序是如何执行的呢?
大概画出如下一个草图表示表 cc4 中的索引示意图:
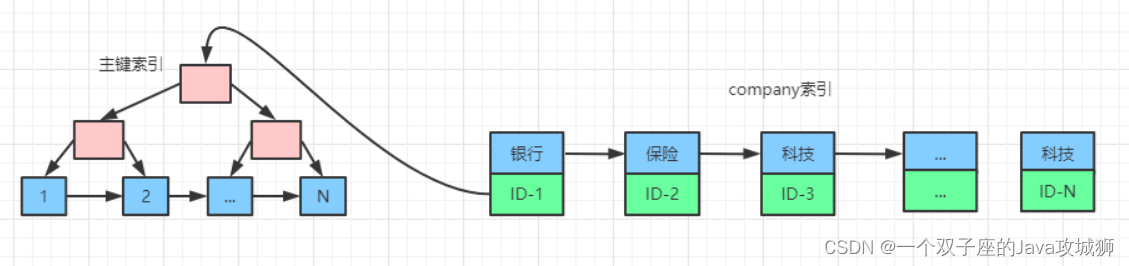
上图中显示 company 字段为普通索引,再加上主键索引,这张表一共有两个索引,所以这条语句是这么执行的:
- 初始化 sort_buffer,并确定好需要放入 user_name ,job,company 这三个字段。
- 从 company 索引中找到第一个满足 company='科技’ 条件的主键 id,也就是上图中的 ID-3。
- 然后执行回表操作,根据 id 值到主键索引中取出整行,然后取出 user_name ,job,company 三个字段的值,并存入sort_buffer 中。
- 从 company 索引中取下一个满足条件记录的主键 id,重复步骤 3 。
- 继续重复 步骤 4 和 3,直到 company 的值不满足查询条件为止。
- 对 sort_buffer 中的数据按照字段 user_name 做快速排序,最后按照排序结果取前 1000 行返回给客户端。
这种排序方式称之为全字段排序法。
上面步骤中的第 6 步,排序可以在内存中进行,如果内存足够的话,而内存是否足够则取决于 sort_buffer_size 的值,但是我们想一下,如果排序的数据量太大,我们不可能提供足够的内存,那么这时候就不得不使用磁盘的临时文件来进行排序。
那么我们如何知道当前的排序语句是使用文件完成排序还是使用内存来完成排序呢?
接下来我们执行下面两句话:
SET optimizer_trace='enabled=on';-- 打开optimizer_trace,只对本线程有效 SELECT user_name,job,company FROM cc4 WHERE company='科技' ORDER BY user_name LIMIT 1000; SELECT * FROM `information_schema`.`OPTIMIZER_TRACE`\G -- 查看 OPTIMIZER_TRACE 输出
最后这条查询语句会返回非常多的信息,包括了具体的查询步骤,我们看到最后的 filesort_summary:
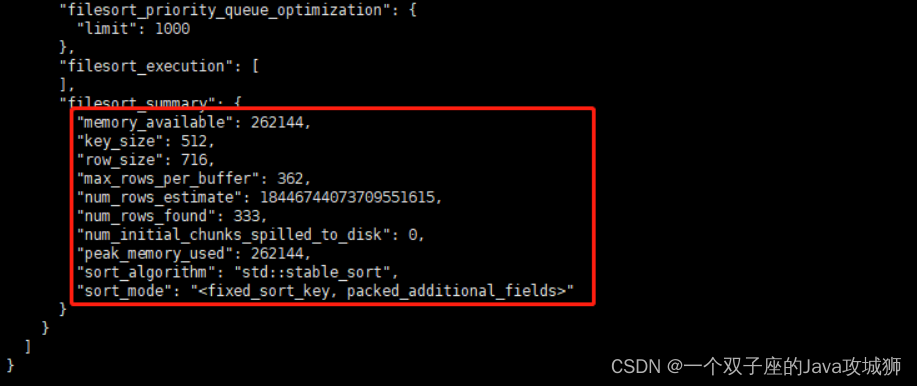
这里面有几个信息比较关键:
- memory_available:表示当前可以用于排序的内存
- num_rows_found:表示有多少条数据参与排序。
- num_initial_chunks_spilled_to_disk:表示产生了多少个临时文件用于排序,0表示当前是全部采用内存排序,这里为什么会产生多个文件的原因是当数据量过大时,MySQL会分散到多个文件进行处理,最后通过归并排序算法来完成完整的排序。
- sort_mode:最后这一列代表当前排序模式,packed_additional_fields代表的就是采用了全字段排序法,而且启用了 pack。
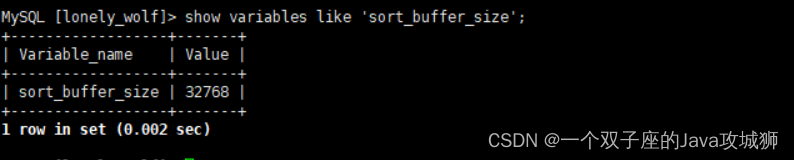
接下来我们把默认的排序内存改小一点:
SET sort_buffer_size=32768; -- 8.0 版本最小值,无法设置成更小,不同版本之间有差异 show variables like 'sort_buffer_size';
执行之后可以看到排序大小已经被修改为 32k:
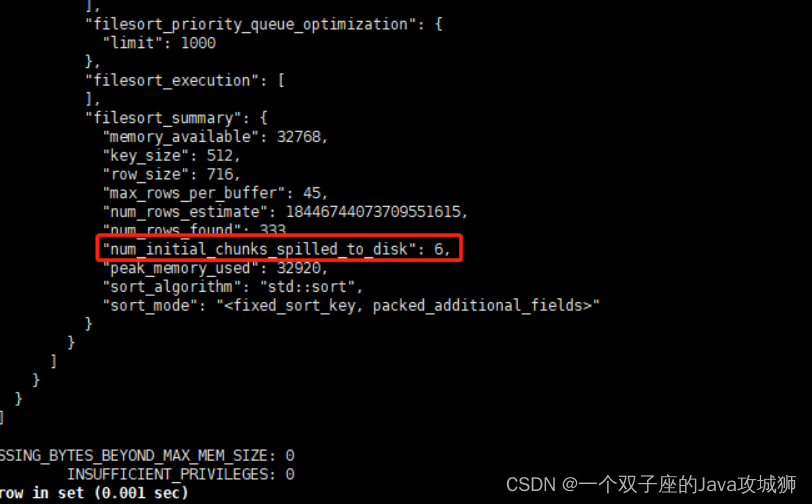
接下来我们再来执行排序查询跟踪
SELECT user_name,job,company FROM cc4 WHERE company='科技' ORDER BY user_name LIMIT 1000; SELECT * FROM `information_schema`.`OPTIMIZER_TRACE`\G -- 查看 OPTIMIZER_TRACE 输出
这时候会发现这时候使用到了 6 个临时文件进行排序:
主键排序法
在前面的全字段排序法中其实有些浪费,因为排序只用到了 user_name 字段,而我们却同时查询了其他字段,这些字段查询出来都是会占用空间的,尤其是当查询的字段很多,或者有些字段又特别长的时候,会占用很大空间,导致不得不使用文件排序,而由于字段多又长,就会造成文件个数增多,从而导致排序性能会更差。
上面的查询语句中,我们有没有办法不把一些无用的字段也放到 sort_buffer 中呢?
在 MySQL 中提供了一个字段 max_length_for_sort_data,默认是 4096
show variables like 'max_length_for_sort_data';
这个字段是控制用于排序的行数据的长度的一个参数。如果用于排序的单行数据长度超过这个值,MySQL 就认为单行数据太大了,要换一个算法,采用 rowid 算法。
采用 rowid 算法的步骤如下:
- 初始化 sort_buffer,并确定好需要放入 user_name ,id 这两个字段。
- 从 company 索引中找到第一个满足 company='科技’ 条件的主键 id,也就是上图中的 ID-3。
- 然后执行回表操作,根据 id 值到主键索引中查找出整行数据,然后取出 user_name ,id 这两个字段的值,并存入sort_buffer 中。
- 从 company 索引中取下一个满足条件记录的主键 id,重复步骤 3 。
- 继续重复 步骤 4 和 3,直到 company 的值不满足查询条件为止。
- 对 sort_buffer 中的数据按照字段 user_name 做快速排序。
- 遍历排序结果,取前 1000 行数据,并根据主键 id 进行回表查询,取出 user_name,job 和 company三个字段返回给客户端。
这种排序方式对比前面一种全字段排序,我们发现存的数据更少了,所以需要的内存空间更少,但是又有一个更大的问题就是这里需要进行两次回表操作,当数据量过大,这也会造成性能影响。
所以我们再结合前面学习的知识,如果排序的时候可以采用覆盖索引,那么就不需要进行回表操作,从而大幅度提升性能,这也是覆盖索引的威力。
如何避免 filesort
首先我们看下面一个例子,执行以下语句:
DROP INDEX company_index ON cc4;-- 删除索引 CREATE INDEX company_user_index ON cc4 (company,user_name);-- 创建联合索引 explain SELECT user_name,job,company FROM cc4 WHERE company='科技' ORDER BY user_name LIMIT 1000;
执行结果如下:

可以看到,这次就没有用到 filesort 了,这是为什么呢?
因为我们创建了一个联合索引,而 MySQL 中的 B+ 树索引是天然有序的,所以当指定了 company,按顺序找到的数据,就是按照 user_name 进行的排序,也就不需要再执行一次排序操作了。
到此这篇关于MySQL中如何优化order by语句的文章就介绍到这了,更多相关MySQL优化order by内容请搜索以前的文章或继续浏览下面的相关文章希望大家以后多多支持!
若文章对您有帮助,帮忙点个赞!
(微信扫码即可登录,无需注册)