ШчКЮЭЈЙ§PythonХРГцХРбщжЄТыЃП
жївЊЪЕЯжЙІФмЃК
- ЕЧТНЭјвГ
- ЖЏЬЌЕШД§ЭјвГМгди
- бщжЄТыЯТди
КмдчОЭгавЛИіЯыЗЈЃЌОЭЪЧздЖЏАДееНХБОжДаавЛИіЙІФмЃЌНкЪЁДѓСПЕФШЫСІ——ИіШЫБШНЯРСЁЃЛЈСЫМИЬьаДСЫаДЃЌБОзХЯыЭъГЩбщжЄТыЕФЪЖБ№ЃЌДгИљБОЩЯНтОіЮЪЬтЃЌжЛЪЧФбЖШЬЋИпЃЌЪЖБ№ЕФзМШЗТЪгжЬЋЕЭЃЌМЦЛЎдйДЮИцвЛЖЮТфЁЃ
ЯЃЭћетДЮОРњПЩвдгыДѓМвНјааЗжЯэКЭНЛСїЁЃ
PythonДђПЊфЏРРЦї
ЯрБШгыздДјЕФurllib2ФЃПщЃЌВйзїБШНЯТщЗГЃЌеыЖдгквЛВПЗжЭјвГЛЙашвЊЖдcookieНјааБЃДцЃЌКмВЛЗНБуЁЃгкЪЧЃЌЮветРяЪЙгУЕФЪЧPython2.7ЯТЕФseleniumФЃПщНјааЭјвГЩЯЕФВйзїЁЃ
ВтЪдЭјвГЃКhttp://graduate.buct.edu.cn
ДђПЊЭјвГЃКЃЈашЯТдиchromedriverЃЉ
ЮЊСЫжЇГжжаЮФзжЗћЪфГіЃЌЮвУЧашвЊЕїгУsysФЃПщЃЌАбФЌШЯБрТыИФЮЊ UTF-8
<code class="hljs python">from selenium.webdriver.support.ui import Select, WebDriverWait
from selenium import webdriver
from selenium import common
from PIL import Image
import pytesser
import sys
reload(sys)
sys.setdefaultencoding('utf8')
broswer = webdriver.Chrome()
broswer.maximize_window()
username = 'test'
password = 'test'
url = 'http://graduate.buct.edu.cn'
broswer.get(url)</code>
ЕШД§ЭјвГМгдиЭъБЯ
ЪЙгУЕФЪЧseleniumжаЕФWebDriverWaitЃЌЩЯУцЕФДњТыжавбОМгди
<code class="hljs livecodeserver">url = 'http://graduate.buct.edu.cn' broswer.get(url) wait = WebDriverWait(webdriver,5) #ЩшжУГЌЪБЪБМф5s # дкетРяЪфШыБэЕЅЬюаДВЂМгдиЕФДњТы elm = wait.until(lambda webdriver: broswer.find_element_by_xpath(xpathMenuCheck))</code>
дЊЫиЖЈЮЛЁЂзжЗћЪфШы
етРяЮвУЧПДЕНгавЛИіvalue = “1”ЃЌПМТЧЕНЯТРПђЕФЪєадЃЌЮвУЧжЛвЊЯыАьЗЈАбетИіvalueИГжЕИјUserRoleОЭКУСЫЁЃ
етРяЪЙгУЕФЪЧЭЈЙ§seleniumЕФSelectФЃПщРДНјаабЁдёЃЌЖЈЮЛПиМўЪЙгУ find_element_by_**ЃЌФмвЛвЛЖдгІЃЌКмЗНБуЁЃ
<code class="hljs sql">select = Select(broswer.find_element_by_id('UserRole'))
select.select_by_value('2')
name = broswer.find_element_by_id('username')
name.send_keys(username)
pswd = broswer.find_element_by_id('password')
pswd.send_keys(password)
btnlg = broswer.find_element_by_id('btnLogin')
btnlg.click()</code>
етЪЧгУНХБОздЖЏЬюГфЭъЕФаЇЙћЃЌжЎКѓОЭЛсзЊЬјЕНЯТвЛвГЁЃ
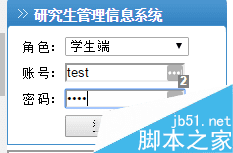
етРяЃЌЮвашвЊЕФЪЧЙІФмЪЧздЖЏЖдбЇЪѕБЈИцНјааБЈУћ
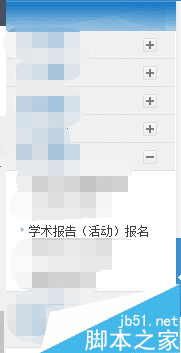
ЖдашвЊвбгаЕФБЈИцгвМќМДПЩЗЂЯжКЭетИіЛюЖЏгаЙиЕФЯћЯЂЃЌвђЯждкУЛгаБЈИцЃЌЫљвджЛЯдЪОСЫБъЬтЃЌЕЋЖдгкКѓУцЕФгааЇБЈИцЪЖБ№гаЯрЫЦЕФЕиЗНЁЃ

ЖдгкдЊЫиЕФЖЈЮЛЃЌЮвгХЯШбЁдёСЫ xpathЃЌИљОнВтЪдЃЌПЩвдЮЈвЛЖЈЮЛвЛИідЊЫиЕФЮЛжУЃЌКмКУгУЁЃ
<code class="hljs perl">//*[@id="dgData00"]/tbody/tr/td[2] ЃЈЧАУцЪЧxpathЃЉ</code>
ХРШЁаХЯЂ
НгЯТРДЮвУЧвЊНјааЕФВНжшЪЧХРШЁЯжгаЕФгааЇБЈИцЃК
<code class="hljs axapta"># бАевгааЇБЈИц
flag = 1
count = 2
count_valid = 0
while flag:
try:
category = broswer.find_element_by_xpath('//*[@id="dgData00"]/tbody/tr[' + str(count) + ']/td[1]').text
count += 1
except common.exceptions.NoSuchElementException:
break
# ЛёШЁБЈИцаХЯЂ
flag = 1
for currentLecture in range(2, count):
# РрБ№
category = broswer.find_element_by_xpath('//*[@id="dgData00"]/tbody/tr[' + str(currentLecture) + ']/td[1]').text
# УћГЦ
name = broswer.find_element_by_xpath('//*[@id="dgData00"]/tbody/tr[' + str(currentLecture) + ']/td[2]').text
# ЕЅЮЛ
unitsPublish = broswer.find_element_by_xpath('//*[@id="dgData00"]/tbody/tr[' + str(currentLecture) + ']/td[3]').text
# ПЊЪМЪБМф
startTime = broswer.find_element_by_xpath('//*[@id="dgData00"]/tbody/tr[' + str(currentLecture) + ']/td[4]').text
# НижЙЪБМф
endTime = broswer.find_element_by_xpath('//*[@id="dgData00"]/tbody/tr[' + str(currentLecture) + ']/td[5]').text</code>
ХРШЁбщжЄТы
ЖдЭјвГжаЕФбщжЄТыНјаадЊЫиЩѓВщКѓЃЌЮвУЧЗЂЯжСЫЦфжаЕФвЛИівЛИіСДНгЃЌЪЧ IdentifyingCode.apsxЃЌКѓУцЮвУЧОЭЖдетИівГУцНјааМгдиЃЌВЂХњСПЛёШЁбщжЄТыЁЃ
ХРШЁЕФЫМТЗЪЧгУseleniumНиШЁЕБЧАвГУцЃЈНіЯдЪОВПЗжЃЉЃЌВЂБЃДцЕНБОЕи——ашвЊЗвГВЂНиШЁЬиЖЈЮЛжУЕФЧыбаОПЃК
broswer.set_window_position(**)ЯрЙиКЏЪ§ЃЛШЛКѓШЫЙЄНјаабщжЄТыЕФЖЈЮЛЃЌЭЈЙ§PILФЃПщНјааНиШЁВЂБЃДцЁЃ
зюКѓЕїгУЙШИшдкPythonЯТЕФpytesserНјаазжЗћЪЖБ№ЃЌЕЋетИіЭјеОЕФбщжЄТыгаКмЖрЕФИЩШХЃЌЭтМгзжЗћа§зЊЃЌНіНіФмЪЖБ№ЦфжаЕФвЛВПЗжзжЗћЁЃ
<code class="hljs livecodeserver"># ЛёШЁбщжЄТыВЂбщжЄЃЈНіНівЛЗљЃЉ
authCodeURL = broswer.find_element_by_xpath('//*[@id="Table2"]/tbody/tr[2]/td/p/img').get_attribute('src') # ЛёШЁбщжЄТыЕижЗ
broswer.get(authCodeURL)
broswer.save_screenshot('text.png')
rangle = (0, 0, 64, 28)
i = Image.open('text.png')
frame4 = i.crop(rangle)
frame4.save('authcode.png')
qq = Image.open('authcode.png')
text = pytesser.image_to_string(qq).strip()</code>
<code class="hljs axapta"># ХњСПЛёШЁбщжЄТы
authCodeURL = broswer.find_element_by_xpath('//*[@id="Table2"]/tbody/tr[2]/td/p/img').get_attribute('src') # ЛёШЁбщжЄТыЕижЗ
# ЛёШЁбЇЯАбљБО
for count in range(10):
broswer.get(authCodeURL)
broswer.save_screenshot('text.png')
rangle = (1, 1, 62, 27)
i = Image.open('text.png')
frame4 = i.crop(rangle)
frame4.save('authcode' + str(count) + '.png')
print 'count:' + str(count)
broswer.refresh()
broswer.quit()</code>
ХРШЁЯТРДЕФбщжЄТы
ДгЩЯУцЕФбщжЄТыПДГіЃЌзжЗћЪЧДја§зЊЕФЃЌЖјЧввђЮЊа§зЊдьГЩЕФжиЕўЖдгкКѓајЕФЪЖБ№вВгаКмДѓЕФгАЯьЁЃЮвдјГЂЪдЙ§ЪЙгУЩёОЭјТчНјаабЕСЗЃЌЕЋвђУЛгаНјааЬиеїЯђСПЕФЬсШЁЃЌзМШЗТЪЕЭЕУРыЦзЁЃ
ЙигкPythonХРГцХРбщжЄТыЪЕЯжЙІФмЯъНтОЭИјДѓМвНщЩмЕНетРяЃЌЯЃЭћЖдДѓМвгаЫљАяжњЃЁ
БОЮФЕижЗЃКhttp://www.45fan.com/a/question/76080.html