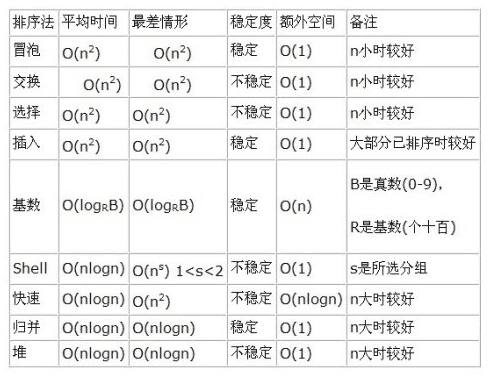
pythonЕЕРтЛг·ЁөД·Ҫ·ЁҪйЙЬ
ЧЬҪбБЛТ»ПВіЈјыјҜЦРЕЕРтөДЛг·Ё
№йІўЕЕРт
№йІўЕЕРтТІіЖәПІўЕЕРтЈ¬КЗ·ЦЦО·ЁөДөдРНУҰУГЎЈ·ЦЦОЛјПлКЗҪ«ГҝёцОКМв·ЦҪвіЙёцёцРЎОКМвЈ¬Ҫ«ГҝёцРЎОКМвҪвҫцЈ¬И»әуәПІўЎЈ
ҫЯМеөД№йІўЕЕРтҫНКЗЈ¬Ҫ«Т»ЧйОЮРтКэ°ҙn/2өЭ№й·ЦҪвіЙЦ»УРТ»ёцФӘЛШөДЧУПоЈ¬Т»ёцФӘЛШҫНКЗТСҫӯЕЕәГРтөДБЛЎЈИ»әуҪ«ХвР©УРРтөДЧУФӘЛШҪшРРәПІўЎЈ
әПІўөД№эіМҫНКЗ ¶Ф БҪёцТСҫӯЕЕәГРтөДЧУРтБРЈ¬ПИСЎИЎБҪёцЧУРтБРЦРЧоРЎөДФӘЛШҪшРРұИҪПЈ¬СЎИЎБҪёцФӘЛШЦРЧоРЎөДДЗёцЧУРтБРІўҪ«ЖдҙУЧУРтБРЦР
ИҘөфМнјУөҪЧоЦХөДҪб№ыјҜЦРЈ¬ЦұөҪБҪёцЧУРтБР№йІўНкіЙЎЈ
ҙъВлИзПВЈә
#!/usr/bin/python import sys def merge(nums, first, middle, last): ''''' merge ''' # ЗРЖ¬ұЯҪз,ЧуұХУТҝӘІўЗТКЗБЛ0ОӘҝӘКј lnums = nums[first:middle+1] rnums = nums[middle+1:last+1] lnums.append(sys.maxint) rnums.append(sys.maxint) l = 0 r = 0 for i in range(first, last+1): if lnums[l] < rnums[r]: nums[i] = lnums[l] l+=1 else: nums[i] = rnums[r] r+=1 def merge_sort(nums, first, last): ''''' merge sort merge_sortәҜКэЦРҙ«өЭөДКЗПВұкЈ¬І»КЗФӘЛШёцКэ ''' if first < last: middle = (first + last)/2 merge_sort(nums, first, middle) merge_sort(nums, middle+1, last) merge(nums, first, middle,last) if __name__ == '__main__': nums = [10,8,4,-1,2,6,7,3] print 'nums is:', nums merge_sort(nums, 0, 7) print 'merge sort:', nums
ОИ¶ЁЈ¬КұјдёҙФУ¶И O(nlog n)
ІеИлЕЕРт
ҙъВлИзПВЈә
#!/usr/bin/python importsys definsert_sort(a): ''''' ІеИлЕЕРт УРТ»ёцТСҫӯУРРтөДКэҫЭРтБРЈ¬ТӘЗуФЪХвёцТСҫӯЕЕәГөДКэҫЭРтБРЦРІеИлТ»ёцКэЈ¬ ө«ТӘЗуІеИләуҙЛКэҫЭРтБРИФИ»УРРтЎЈёХҝӘКј Т»ёцФӘЛШПФИ»УРРтЈ¬И»әуІеИлТ» ёцФӘЛШөҪККөұО»ЦГЈ¬И»әуФЩІеИлөЪИэёцФӘЛШЈ¬ТАҙОАаНЖ ''' a_len = len(a) if a_len = 0 and a[j] > key: a[j+1] = a[j] j-=1 a[j+1] = key return a if __name__ == '__main__': nums = [10,8,4,-1,2,6,7,3] print 'nums is:', nums insert_sort(nums) print 'insert sort:', nums
ОИ¶ЁЈ¬КұјдёҙФУ¶И O(n^2)
Ҫ»»»БҪёцФӘЛШөДЦөpythonЦРДгҝЙТФХвГҙРҙЈәa, b = b, aЈ¬ЖдКөХвКЗТтОӘёіЦө·ыәЕөДЧуУТБҪұЯ¶јКЗФӘЧй
ЈЁХвАпРиТӘЗҝөчөДКЗЈ¬ФЪpythonЦРЈ¬ФӘЧйЖдКөКЗУЙ¶әәЕ“,”АҙҪз¶ЁөДЈ¬¶шІ»КЗАЁәЕЈ©ЎЈ
СЎФсЕЕРт
СЎФсЕЕРт(Selection sort)КЗТ»ЦЦјтөҘЦұ№ЫөДЕЕРтЛг·ЁЎЈЛьөД№ӨЧчФӯАнИзПВЎЈКЧПИФЪОҙЕЕРтРтБРЦРХТөҪЧоРЎЈЁҙуЈ©ФӘЛШЈ¬ҙж·ЕөҪ
ЕЕРтРтБРөДЖрКјО»ЦГЈ¬И»әуЈ¬ФЩҙУКЈУаОҙЕЕРтФӘЛШЦРјМРшС°ХТЧоРЎЈЁҙуЈ©ФӘЛШЈ¬И»әу·ЕөҪТСЕЕРтРтБРөДД©ОІЎЈТФҙЛАаНЖЈ¬ЦұөҪЛщ
УРФӘЛШҫщЕЕРтНкұПЎЈ
import sys
def select_sort(a):
''''' СЎФсЕЕРт
ГҝТ»МЛҙУҙэЕЕРтөДКэҫЭФӘЛШЦРСЎіцЧоРЎЈЁ»тЧоҙуЈ©өДТ»ёцФӘЛШЈ¬
ЛіРт·ЕФЪТСЕЕәГРтөДКэБРөДЧоәуЈ¬ЦұөҪИ«ІҝҙэЕЕРтөДКэҫЭФӘЛШЕЕНкЎЈ
СЎФсЕЕРтКЗІ»ОИ¶ЁөДЕЕРт·Ҫ·ЁЎЈ
'''
a_len=len(a)
for i in range(a_len):#ФЪ0-n-1ЙПТАҙОСЎФсПаУҰҙуРЎөДФӘЛШ
min_index = i#јЗВјЧоРЎФӘЛШөДПВұк
for j in range(i+1, a_len):#ІйХТЧоРЎЦө
if(a[j]<a[min_index]):
min_index=j
if min_index != i:#ХТөҪЧоРЎФӘЛШҪшРРҪ»»»
a[i],a[min_index] = a[min_index],a[i]
if __name__ == '__main__':
A = [10, -3, 5, 7, 1, 3, 7]
print 'Before sort:',A
select_sort(A)
print 'After sort:',A
І»ОИ¶ЁЈ¬КұјдёҙФУ¶И O(n^2)
ПЈ¶ыЕЕРт
ПЈ¶ыЕЕРтЈ¬ТІіЖөЭјхФцБҝЕЕРтЛг·Ё,ПЈ¶ыЕЕРтКЗ·ЗОИ¶ЁЕЕРтЛг·ЁЎЈёГ·Ҫ·ЁУЦіЖЛхРЎФцБҝЕЕРтЈ¬ТтDLЈ®ShellУЪ1959ДкМбіц¶шөГГыЎЈ
ПИИЎТ»ёцРЎУЪnөДХыКэd1ЧчОӘөЪТ»ёцФцБҝЈ¬°СОДјюөДИ«ІҝјЗВј·ЦіЙd1ёцЧйЎЈЛщУРҫаАлОӘd1өДұ¶КэөДјЗВј·ЕФЪН¬Т»ёцЧйЦРЎЈПИФЪёчЧйДЪҪшРРЕЕРтЈ»
И»әуЈ¬ИЎөЪ¶юёцФцБҝd2
import sys
def shell_sort(a):
''''' shellЕЕРт
'''
a_len=len(a)
gap=a_len/2#ФцБҝ
while gap>0:
for i in range(a_len):#¶ФН¬Т»ёцЧйҪшРРСЎФсЕЕРт
m=i
j=i+1
while j<a_len:
if a[j]<a[m]:
m=j
j+=gap#jФцјУgap
if m!=i:
a[m],a[i]=a[i],a[m]
gap/=2
if __name__ == '__main__':
A = [10, -3, 5, 7, 1, 3, 7]
print 'Before sort:',A
shell_sort(A)
print 'After sort:',A
І»ОИ¶ЁЈ¬КұјдёҙФУ¶И ЖҪҫщКұјд O(nlogn) ЧоІоКұјдO(n^s)1
¶СЕЕРт ( Heap Sort )
“¶С”өД¶ЁТеЈәФЪЖрКјЛчТэОӘ 0 өД“¶С”ЦРЈә
ҪЪөг i өДУТЧУҪЪөгФЪО»ЦГ 2 * i + 24) ҪЪөг i өДёёҪЪөгФЪО»ЦГ floor( (i – 1) / 2 ) : Чў floor ұнКҫ“ИЎХы”ІЩЧч
¶СөДМШРФЈә
ГҝёцҪЪөгөДјьЦөТ»¶ЁЧЬКЗҙуУЪЈЁ»тРЎУЪЈ©ЛьөДёёҪЪөг
“Чоҙу¶С”Јә
“¶С”өДёщҪЪөгұЈҙжөДКЗјьЦөЧоҙуөДҪЪөгЎЈјҙ“¶С”ЦРГҝёцҪЪөгөДјьЦө¶јЧЬКЗҙуУЪЛьөДЧУҪЪөгЎЈ
ЙПТЖЈ¬ПВТЖ Јә
өұДіҪЪөгөДјьЦөҙуУЪЛьөДёёҪЪөгКұЈ¬ХвКұОТГЗҫНТӘҪшРР“ЙПТЖ”ІЩЧчЈ¬јҙОТГЗ°СёГҪЪөгТЖ¶ҜөҪЛьөДёёҪЪөгөДО»ЦГЈ¬¶шИГЛьөДёёҪЪөгөҪЛьөДО»ЦГЙПЈ¬И»әуОТГЗјМРшЕР¶ПёГҪЪөгЈ¬ЦұөҪёГҪЪөгІ»ФЩҙуУЪЛьөДёёҪЪөгОӘЦ№ІЕНЈЦ№“ЙПТЖ”ЎЈ
ПЦФЪОТГЗФЩАҙБЛҪвТ»ПВ“ПВТЖ”ІЩЧчЎЈөұОТГЗ°СДіҪЪөгөДјьЦөёДРЎБЛЦ®әуЈ¬ОТГЗҫНТӘ¶ФЖдҪшРР“ПВТЖ”ІЩЧчЎЈ
·Ҫ·ЁЈә
ОТГЗКЧПИҪЁБўТ»ёцЧоҙу¶С(КұјдёҙФУ¶ИO(n))Ј¬И»әуГҝҙООТГЗЦ»РиТӘ°СёщҪЪөгУлЧоәуТ»ёцО»ЦГөДҪЪөгҪ»»»Ј¬И»әу°СЧоәуТ»ёцО»ЦГЕЕіэЦ®НвЈ¬И»әу°СҪ»»»әуёщҪЪөгөД¶СҪшРРөчХы(КұјдёҙФУ¶И O(lgn) )Ј¬јҙ¶ФёщҪЪөгҪшРР“ПВТЖ”ІЩЧчјҙҝЙЎЈ ¶СЕЕРтөДЧЬөДКұјдёҙФУ¶ИОӘO(nlgn).
ҙъВлИзПВЈә
#!/usr/bin env python # КэЧйұаәЕҙУ 0ҝӘКј def left(i): return 2*i +1 def right(i): return 2*i+2 #ұЈіЦЧоҙу¶СРФЦК К№ТФiОӘёщөДЧУКчіЙОӘЧоҙу¶С def max_heapify(A, i, heap_size): if heap_size <= 0: return l = left(i) r = right(i) largest = i # СЎіцЧУҪЪөгЦРҪПҙуөДҪЪөг if l A[largest]: largest = l if r A[largest]: largest = r if i != largest :#ЛөГчөұЗ°ҪЪөгІ»КЗЧоҙуөДЈ¬ПВТЖ A[i], A[largest] = A[largest], A[i] #Ҫ»»» max_heapify(A, largest, heap_size)#јМРшЧ·ЧЩПВТЖөДөг #print A # ҪЁ¶С def bulid_max_heap(A): heap_size = len(A) if heap_size >1: node = heap_size/2 -1 while node >= 0: max_heapify(A, node, heap_size) node -=1 # ¶СЕЕРт ПВұкҙУ0ҝӘКј def heap_sort(A): bulid_max_heap(A) heap_size = len(A) i = heap_size - 1 while i > 0 : A[0],A[i] = A[i], A[0] # ¶СЦРөДЧоҙуЦөҙжИлКэЧйККөұөДО»ЦГЈ¬ІўЗТҪшРРҪ»»» heap_size -=1 # heap ҙуРЎ өЭјх 1 i -= 1 # ҙж·Е¶СЦРЧоҙуЦөөДПВұкөЭјх 1 max_heapify(A, 0, heap_size) if __name__ == '__main__' : A = [10, -3, 5, 7, 1, 3, 7] print 'Before sort:',A heap_sort(A) print 'After sort:',A
І»ОИ¶ЁЈ¬КұјдёҙФУ¶И O(nlog n)
ҝмЛЩЕЕРт
ҝмЛЩЕЕРтЛг·ЁәНәПІўЕЕРтЛг·ЁТ»СщЈ¬ТІКЗ»щУЪ·ЦЦОДЈКҪЎЈ¶ФЧУКэЧйA[p…r]ҝмЛЩЕЕРтөД·ЦЦО№эіМөДИэёцІҪЦиОӘЈә
·ЦҪвЈә°СКэЧйA[p…r]·ЦОӘA[p…q-1]УлA[q+1…r]БҪІҝ·ЦЈ¬ЖдЦРA[p…q-1]ЦРөДГҝёцФӘЛШ¶јРЎУЪөИУЪA[q]¶шA[q+1…r]ЦРөДГҝёцФӘЛШ¶јҙуУЪөИУЪA[q]Ј»
ҪвҫцЈәНЁ№эөЭ№йөчУГҝмЛЩЕЕРтЈ¬¶ФЧУКэЧйA[p…q-1]әНA[q+1…r]ҪшРРЕЕРтЈ»
әПІўЈәТтОӘБҪёцЧУКэЧйКЗҫНөШЕЕРтөДЈ¬ЛщТФІ»РиТӘ¶оНвөДІЩЧчЎЈ
¶ФУЪ»®·Цpartition ГҝТ»ВЦөьҙъөДҝӘКјЈ¬x=A[r], ¶ФУЪИОәОКэЧйПВұкkЈ¬УРЈә
1) Из№ыp≤k≤iЈ¬ФтA[k]≤xЎЈ
2) Из№ыi+1≤k≤j-1Ј¬ФтA[k]>xЎЈ
3) Из№ыk=rЈ¬ФтA[k]=xЎЈ
ҙъВлИзПВЈә
#!/usr/bin/env python # ҝмЛЩЕЕРт ''''' »®·Ц К№ВъЧг ТФA[r]ОӘ»щЧј¶ФКэЧйҪшРРТ»ёц»®·ЦЈ¬ұИA[r]РЎөД·ЕФЪЧуұЯЈ¬ ұИA[r]ҙуөД·ЕФЪУТұЯ ҝмЛЩЕЕРтөД·ЦЦОpartition№эіМУРБҪЦЦ·Ҫ·ЁЈ¬ Т»ЦЦКЗЙПГжЛщКцөДБҪёцЦёХлЛчТэТ»З°Т»әуЦрІҪПтәуЙЁГиөД·Ҫ·Ё, БнТ»ЦЦ·Ҫ·ЁКЗБҪёцЦёХлҙУКЧО»ПтЦРјдЙЁГиөД·Ҫ·ЁЎЈ ''' #p,r КЗКэЧйAөДПВұк def partition1(A, p ,r): ''''' ·Ҫ·ЁТ»Ј¬БҪёцЦёХлЛчТэТ»З°Т»әуЦрІҪПтәуЙЁГиөД·Ҫ·Ё ''' x = A[r] i = p-1 j = p while j < r: if A[j] < x: i +=1 A[i], A[j] = A[j], A[i] j += 1 A[i+1], A[r] = A[r], A[i+1] return i+1 def partition2(A, p, r): ''''' БҪёцЦёХлҙУКЧОІПтЦРјдЙЁГиөД·Ҫ·Ё ''' i = p j = r x = A[p] while i = x and i < j: j -=1 A[i] = A[j] while A[i]<=x and i < j: i +=1 A[j] = A[i] A[i] = x return i # quick sort def quick_sort(A, p, r): ''''' ҝмЛЩЕЕРтөДЧоІоКұјдёҙФУ¶ИОӘO(n2)Ј¬ЖҪКұКұјдёҙФУ¶ИОӘO(nlgn) ''' if p < r: q = partition2(A, p, r) quick_sort(A, p, q-1) quick_sort(A, q+1, r) if __name__ == '__main__': A = [5,-4,6,3,7,11,1,2] print 'Before sort:',A quick_sort(A, 0, 7) print 'After sort:',A
І»ОИ¶ЁЈ¬КұјдёҙФУ¶И ЧоАнПл O(nlogn)ЧоІоКұјдO(n^2)
ЛөПВpythonЦРөДРтБРЈә
БРұнЎўФӘЧйәНЧЦ·ыҙ®¶јКЗРтБРЈ¬ө«КЗРтБРКЗКІГҙЈ¬ЛьГЗОӘКІГҙИзҙЛМШұрДШЈҝРтБРөДБҪёцЦчТӘМШөгКЗЛчТэІЩЧч·ыәНЗРЖ¬ІЩЧч·ыЎЈЛчТэІЩЧч·ыИГОТГЗҝЙТФҙУРтБРЦРЧҘИЎТ»ёцМШ¶ЁПоДҝЎЈЗРЖ¬ІЩЧч·ыИГОТГЗДЬ№»»сИЎРтБРөДТ»ёцЗРЖ¬Ј¬јҙТ»Іҝ·ЦРтБР,ИзЈәa = [‘aa','bb','cc'], print a[0] ОӘЛчТэІЩЧчЈ¬print a[0:2]ОӘЗРЖ¬ІЩЧчЎЈ
ПЈНыНЁ№эҙЛОДХЖОХPython Лг·ЁЕЕРтөДЦӘК¶Ј¬Р»Р»ҙујТ¶ФұҫХҫөДЦ§іЦЈЎ
ұҫОДөШЦ·Јәhttp://www.45fan.com/a/question/82136.html