爬虫及绕过网站反爬机制内容介绍
爬虫是什么呢,简单而片面的说,爬虫就是由计算机自动与服务器交互获取数据的工具。爬虫的最基本就是get一个网页的源代码数据,如果更深入一些,就会出现和网页进行POST交互,获取服务器接收POST请求后返回的数据。一句话,爬虫用来自动获取源数据,至于更多的数据处理等等是后续的工作,这篇文章主要想谈谈爬虫获取数据的这一部分。爬虫请注意网站的Robot.txt文件,不要让爬虫违法,也不要让爬虫对网站造成伤害。
反爬及反反爬概念的不恰当举例
基于很多原因(如服务器资源,保护数据等),很多网站是限制了爬虫效果的。
考虑一下,由人来充当爬虫的角色,我们怎么获取网页源代码?最常用的当然是右键源代码。
网站屏蔽了右键,怎么办?

拿出我们做爬虫中最有用的东西 F12(欢迎讨论)
同时按下F12就可以打开了(滑稽)
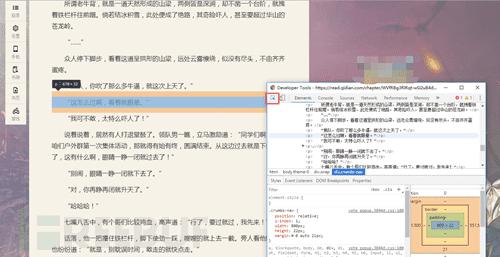
源代码出来了!!
在把人当作爬虫的情况下,屏蔽右键就是反爬取策略,F12就是反反爬取的方式。
讲讲正式的反爬取策略
事实上,在写爬虫的过程中一定出现过没有返回数据的情况,这种时候也许是服务器限制了UA头(user-agent),这就是一种很基本的反爬取,只要发送请求的时候加上UA头就可以了…是不是很简单?
其实一股脑把需要不需要的Request Headers都加上也是一个简单粗暴的办法……
有没有发现网站的验证码也是一个反爬取策略呢?为了让网站的用户能是真人,验证码真是做了很大的贡献。随验证码而来的,验证码识别出现了。
说到这,不知道是先出现了验证码识别还是图片识别呢?
简单的验证码现在识别起来是非常简单的,网上有太多教程,包括稍微进阶一下的去噪,二值,分割,重组等概念。可是现在网站人机识别已经越发的恐怖了起来,比如这种:
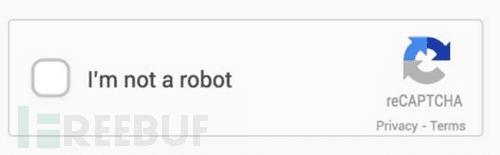
简单讲述一下去噪二值的概念
将一个验证码
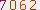
变成
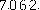
就是二值,也就是将图片本身变成只有两个色调,例子很简单,通过python PIL库里的
Image.convert("1")
就能实现,但如果图片变得更为复杂,还是要多思考一下,比如

如果直接用简单方式的话 就会变成
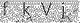
思考一些这种验证码应该怎么识别?这种时候 去噪 就派上了用处,根据验证码本身的特征,可以计算验证码的底色和字体之外的RGB值等,将这些值变成一个颜色,将字体留出。示例代码如下,换色即可
for x in range(0,image.size[0]):
for y in range(0,image.size[1]):
# print arr2[x][y]
if arr[x][y].tolist()==底色:
arr[x][y]=0
elif arr[x][y].tolist()[0] in range(200,256) and arr[x][y].tolist()[1] in range(200,256) and arr[x][y].tolist()[2] in range(200,256):
arr[x][y]=0
elif arr[x][y].tolist()==[0,0,0]:
arr[x][y]=0
else:
arr[x][y]=255
arr是由numpy得到的,根据图片RGB值得出的矩阵,读者可以自己尝试完善代码,亲自实验一下。
细致的处理之后图片可以变成

识别率还是很高的。
在验证码的发展中,还算清晰的数字字母,简单的加减乘除,网上有轮子可以用,有些难的数字字母汉字,也可以自己造轮子(比如上面),但更多的东西,已经足够写一个人工智能了……(有一种工作就是识别验证码…)
再加一个小提示:有的网站PC端有验证码,而手机端没有…
下一个话题!
反爬取策略中比较常见的还有一种封IP的策略,通常是短时间内过多的访问就会被封禁,这个很简单,限制访问频率或添加IP代理池就OK了,当然,分布式也可以…
IP代理池->左转Google右转baidu,有很多代理网站,虽然免费中能用的不多 但毕竟可以。
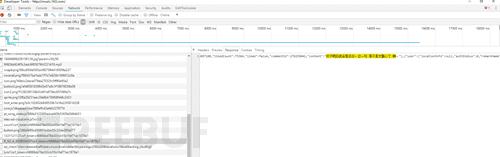
还有一种也可以算作反爬虫策略的就是异步数据,随着对爬虫的逐渐深入(明明是网站的更新换代!),异步加载是一定会遇见的问题,解决方式依然是F12。以不愿透露姓名的网易云音乐网站为例,右键打开源代码后,尝试搜索一下评论

数据呢?!这就是JS和Ajax兴起之后异步加载的特点。但是打开F12,切换到NetWork选项卡,刷新一下页面,仔细寻找,没有秘密。
哦,对了 如果你在听歌的话,点进去还能下载呢…
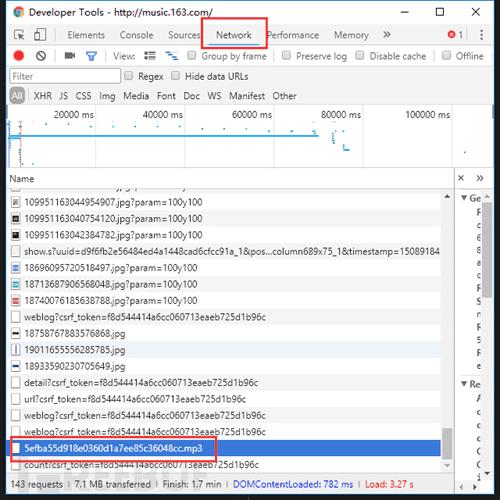
仅为对网站结构的科普,请自觉抵制盗版,保护版权,保护原创者利益。
如果说这个网站限制的你死死的,怎么办?我们还有最后一计,一个强无敌的组合:selenium + PhantomJs
这一对组合非常强力,可以完美模拟浏览器行为,具体的用法自行百度,并不推荐这种办法,很笨重,此处仅作为科普。
总结
本文主要讨论了部分常见的反爬虫策略(主要是我遇见过的(耸肩))。主要包括 HTTP请求头,验证码识别,IP代理池,异步加载几个方面,介绍了一些简单方法(太难的不会!),以Python为主。希望能给初入门的你引上一条路。
本文地址:http://www.45fan.com/a/question/95556.html