 目录
目录发现和纠正托管应用程序中的内存问题可能十分困难。 内存问题的表现形式多种多样。例如,您会观察到,您的应用程序的内存使用量在不断增加,最终导致“内存不足”(OOM) 异常(您的应用程序甚至可能在有大量可用物理内存的情况下引发内存不足异常)。但以下任何一种情况均表明内存可能出现了问题:
- 引发 OutOfMemoryException(内存不足异常)。
- 进程占用了太多内存,您无法确定任何明显的原因。
- 似乎垃圾收集功能并没有快速清理对象。
- 托管堆碎片过多。
- 应用程序过度占用 CPU。
此专栏讨论研究过程,并向您展示如何收集您所需的数据,以确定您所面临的应用程序中的内存问题的类型。此专栏并不包括如何实际修复您所发现的问题,但可以为您提供对问题根源的深入分析。
我们首先简要介绍一下可用于研究托管内存问题的最实用的性能计数器。然后我们会介绍研究过程中常用的工具,接着介绍一系列常见的托管内存问题以及如何研究这些问题。
但在开始之前,您首先应熟悉一些基本概念:
- Microsoft® .NET Framework 中的垃圾收集。有关详细信息,请参阅以下两个博客记录:blogs.msdn.com/156626.aspx 和 blogs.msdn.com/234273.aspx.
- Windows® 中的虚拟内存的工作原理。这包括保留内存和分配内存的概念。
- 使用 Windows 调试程序(WinDbg 和 CDB)。
使用的工具
在开始之前,我们应该花点时间讨论一下在诊断与内存相关的问题时通常使用的一些工具。
性能计数器 通常,您会希望首先了解性能计数器。通过这些计数器,您可以收集必要的数据以确定出现问题的准确位置。虽然有些其他工具也值得关注,但是最有用的性能计数器是 .NET Framework 上介绍的性能计数器。
调试程序 在这里我们将使用 WinDbg,该工具随 Windows 调试工具提供。SOS.dll 中提供的 Son of Strike 扩展 (SOS),用于调试 WinDbg 中的托管代码。在启动了调试程序并将其附加到托管进程(或加载故障转储)后,您可以通过键入以下代码加载 SOS.dll:
.loadby sos mscorwks如果您正在调试的应用程序使用的是不同版本的 mscorwks.dll,则该命令无法执行,那么应找到该应用程序使用的 mscorwks.dll 版本的 SOS.dll,然后运行以下命令:
.load <path_to_sos>/sos.dllSOS.dll 随 .NET Framework 安装在 %windir%/microsoft.net/framework/<.NET 版本> 目录下。SOS.dll 扩展提供了大量用于检查托管堆的有用命令。有关所有这些命令的文档,请参阅 SOS 调试扩展 (SOS.dll)。
Windows 任务管理器 Taskmgr.exe 可方便地发现超出预期的内存使用情况,并可检查在一段时间内一些简单的进程指标的趋势。注意,taskmgr 中有两个经常被误解的指标:Mem Usage (内存使用)和 VM Size(虚拟内存大小)。Mem Usage 表示的是进程工作集(就像进程/工作集性能计数器)。它并不表示所使用的字节数。VM Size 反映的是供进程使用的字节数(就像进程/专用字节数性能计数器)。VM Size 可提供关于您是否面临内存泄漏问题(如果您的应用程序存在泄漏,则 VM Size 会随时间增加)第一线索。
内存转储 在此专栏中介绍的大多数研究技巧都依赖于内存转储。使用调试程序的方法有两种 — 您可以将其附加到正在运行的进程,或利用它来分析故障转储。第一种方法提供了直接的视图,使您可以了解应用程序在运行时的状况,但该技巧并不总是可行的。
内存转储具有可从实际问题研究阶段中分析出数据收集阶段的优点。假设您希望诊断一台实际工作的服务器上的问题,则使用不同的机器脱机分析内存转储可能更容易。
调试程序中的 .dump /ma dmpfile.dmp 命令可用于创建全内存转储。在研究内存问题时确保您始终捕获全转储,因为小型转储并不包含您所需的全部信息。
ADPlus 工具(包含在 Windows 调试工具中)对于收集故障转储有很大帮助。有关详细信息,请参阅从 2005 年 3 月起 John Robbins 的 Bugslayer 专栏。
在本专栏中,我们将假定转储文件始终加载在调试程序中(故障转储可使用 File | Open crash dump 命令加载),或者调试程序始终附加到进程,并且在断点处停止执行。

GC 性能计数器
每项研究的第一步是收集相关数据并对可能存在问题的位置做出假设。通常首先从性能计数器开始。通过 .NET Framework 性能控制台可使用计数器,这些计数器提供了关于垃圾收集器 (GC) 和垃圾收集流程的有用信息。请注意,.NET 内存性能计数器只有在收集时才更新,而不是根据性能监视器应用程序中使用的采样率进行更新。
您应该首先检查 % Time in GC(花在 GC 上的时间的百分比)。它表示自从上次收集结束后 % Time in GC。如果您发现此数值非常高(假设为 50% 或更高),那么您应该检查一下托管堆内部发生了哪些情况。如果 % Time in GC 没有超过 10%,那么通常就不必花时间来尝试减少 GC 用在收集上的时间了,因为这样做带来的益处微乎其微。
如果您认为您的应用程序在执行垃圾收集上花费的时间过多,那么下一个要检查的性能计数器就是 Allocated Bytes/sec(每秒分配字节数)。该计数器显示了分配速率。不过,该计数器在分配速率非常低的情况下,并不十分准确。如果采样频率高于收集频率,该计数器可能显示为 0 字节/秒,因为该计数器只有在每次收集开始的时候进行更新。这并不意味着没有进行分配操作,只是由于在该时间间隔内没有收集发生,因此计数器没有得到更新而已。既然了解到垃圾收集所花费的时间是一个重要的考虑因素,我们将在稍后更详细地了解 % Time in GC。
如果您认为您要收集大量大型对象(85,000 字节或更大),则需要检查大型对象堆 (LOH) 的大校它与 Allocated Bytes/sec 同时更新。
高分配速率会导致大量收集工作,因此可能 % Time in GC 会比较高。能否减轻这一现象的一个因素为对象通常是否很早就死去,只因为它们通常会在第 0 级收集过程中被收集。要确定对象生命周期对收集有何影响,可检查各级收集的性能计数器:# Gen 0 Collections(第 0 级收集次数)、# Gen 1 Collections(第 1 级收集次数)、# Gen 2 Collections(第 2 级收集次数)。这些性能计数器显示自进程启动后对各级对象进行收集的次数。第 0 级和第 1 级收集通常开销很低,因此它们不会对应用程序的性能有很大影响。而第 2 级收集器开销非常大。
首要原则是,各级收集之间合理的比值是每进行 10 次第 1 级收集,进行一次第 2 级收集。如果您发现在垃圾收集上花费了大量时间,那可能是由于第 2 级收集的频率过高造成的。您应该检查上面提到的比值,确保第 2 级收集与第 1 级收集的次数比值不是太高。
您可能会发现 % Time in GC 很高,但分配速率并不高。如果您分配的许多对象能够在垃圾收集后保留下来并被提升到下一级,则会出现这种情况。提升计数器 — 从第 0 级提升的内存 (Promoted Memory from Gen 0) 和从第 1 级提升的内存 (Promoted Memory from Gen 1) — 可以告诉您提升速率是否存在问题。我们希望避免从第 1 级提升的速率太高。这是因为您可能有大量对象存在时间较长,足以提升到第 2 级,但存在的时间不足以使其保留在第 2 级中。一旦提升到第 2 级,这些对象的收集开销就要比它们在第 1 级中死去要大。(这种现象被称为中年危机。有关详细信息,请参阅 blogs.msdn.com/41281.aspx。)CLR 分析器 (CLR Profiler) 可帮您了解哪些对象存在时间过长。
第 1 级和第 2 级堆大小的数值较高往往与提升速率计数器中的数值较高相关。您可以使用第 1 级堆大小和第 2 级堆大小来检查 GC 堆的大校有一个第 0 级堆大小计数器,但它并不用于衡量第 0 级的大校它用于表示第 0 级的空间预算 — 意味着在触发下一次第 0 级收集之前,在第 0 级中您可以分配的字节数。
如果您使用了的大量需要终结的对象 — 例如,依赖于 COM 组件进行一些处理的对象 — 在这种情形下,您可以看一下 Promoted Finalization-Memory from Gen 0(从第 0 级提升的终结内存)计数器。该计数器会告诉您由于使用内存的对象需要被添加到终结队列中而无法立即对其进行收集、由此导致无法被重复使用的内存数量。IDisposable 和 C# 及 Visual Basic® 中的 using 语句可帮助减少在终结队列中结束的对象数量,从而降低相关的开销。
使用 # Total committed Bytes(提供的字节总数)和 # Total reserved Bytes(保留的字节总数)可找到关于堆大小的详细数据。这些计数器分别表示当前在 GC 堆上提供内存和保留内存的总数。(提供的字节总数值略微大于实际的第 0 级堆大小 + 第 1 级堆大小 + 第 2 级堆大小 + 大型对象堆大校)当 GC 分配一个新堆段时,内存将保留给该段,只有在需要时才提供内存。因此保留字节的总数可以比提供的字节总数大。
同样应该检查一下应用程序是否引发了太多次收集。# Induced GC(引发的 GC 的数目)计数器可以告诉您自进程启动以来引发了多少次收集。一般而言,不建议您引发多次 GC 收集。在大多数情况下,如果 # Induced GC 的数值较高,您应该将其视为 Bug。在大多数情况下人们引发 GC 是希望削减堆的大小,但这并非理想的选择。您应该了解您的堆大小为何增加。
Windows 性能计数器
到目前为止,我们已经了解了一些最实用的 .NET 内存计数器。但您不应忽略其他计数器的价值。有很多种 Windows 性能计数器(也可通过 perfmon.exe 查看)为研究内存问题提供了有用的信息。
Memory(内存)类别下面所列的 Available Bytes(可用字节)计数器报告了可用的物理内存。它可明确地显示您的物理内存是否过低。如果机器的物理内存过低,会发生分页或者很快会发生分页。该数据对于诊断 OOM 问题非常有用。
% Committed Bytes in Use(正在使用的字节百分比)计数器(同样位于 Memory 类别下)提供了内存使用量与内存总量的比值。如果此值非常高(假设超过 90%),您应该开始检查提供内存故障。这明显表明系统内存紧张。
Process(进程)类别下的 Private Bytes(专用字节数)计数器表示被使用且无法与其他进程共享的内存数量。如果您希望了解您的进程使用了多少内存,您应该监视此计数器。如果您遇到了内存泄漏问题,专用字节数会随时间增加。该计数器还可明显地表明了您的应用程序对整个系统的影响 — 使用大量专用字节会对机器有很大影响,因为内存无法与其他进程共享。这在某些情形下至关重要,如终端服务,在这种情形下您需要使用户会话之间共享的内存量达到最大。
确认托管进程中的 OOM 异常
性能计数器可向您明确表示您是否正在面临内存问题。但在大多数情况下,只有在您的应用程序中出现内存不足异常的情况下才能检测到内存问题。因此您需要了解您实际上是否正在发生由托管代码引起的 OOM 异常。
在您加载了 SOS.dll 后,可在调试程序中键入以下命令:
!pe这是 !PrintException 的缩写形式。它将输出线程(如果有)上最后的托管异常,无需参数。图1 中显示了 OOM 托管异常的一个示例。
如果当前线程上没有托管异常,您就不必了解 OOM 来自哪个线程了。要了解这一点,请在调试程序中键入以下代码:
~*kb在这里,kb 是 Display Stack Backtrace(显示堆栈回溯)的缩写。它列出了所有线程及其堆栈的调用(参见图2)。在输出中,查找存在异常调用的线程和堆栈。最简便的方法就是查找 mscorwks::RaiseTheException。
mscorwks 中的 RaiseTheException 函数的参数是托管的异常对象。您可以使用 !pe 对其进行转储。此外 !pe 还有一个 –nested 选项,将对除顶级异常之外的所有嵌套异常进行转储。
找出导致 OOM 的线程的另一种方法是使用 SOS 的 !threads 命令。所显示的表的最后一栏将包含各个线程最近引发的托管异常。
如果您使用这些技巧没有找到 OOM 异常,则没有托管 OOM,您所面临的异常由本机代码引发。在这种情况下,您需要关注您的应用程序使用的本机代码(关于此问题的讨论超出了本专栏的范围)。
确定导致 OOM 异常的原因
在您确认了这是 OOM 异常之后,您应该检查导致 OOM 的原因。在两种情形下会出现托管 OOM — 进程耗尽了虚拟内存,或者没有足够的物理内存可提供。
GC 需要为其段分配内存。当 GC 决定它需要分配一个新段时,它会调用 VirtualAlloc 以保留空间。如果段没有连续的足够大的可用块,则调用失败,GC 无法满足新的内存请求。
在调试程序中,!address 命令可为您显示虚拟内存的最大可用区域。输出将类似于:
0:119>!address -summary ... [omitted] Largest free region: Base 54000000 - Size 03b60000 0:119>? 03b60000 Evaluate expression: 62259200 = 03b60000如果在 32 位操作系统上进程可使用的最大可用虚拟内存块小于 64MB(64 位操作系统上小于 1GB),则耗尽虚拟内存可能会导致 OOM(Out of Memory,内存不足)。(在 64 位操作系统上,应用程序不大可能耗尽虚拟内存空间。)
如果虚拟内存的碎片过多,则进程可能会耗尽虚拟空间。通常托管堆不会产生虚拟内存碎片,但也有可能会出现这种情况。例如,如果应用程序创建了大量的临时大型对象,导致 LOH 不断获得和释放虚拟内存段,那么就有可能出现这种情况。
!eeheap –gc SOS 命令将为您显示每个垃圾收集段的起始位置。您可以将其与 !address 的输出关联考虑,以确定虚拟内存的碎片是否由托管堆造成。
以下是其他一些可能导致产生虚拟内存碎片的常见情况。
- 总是加载和卸载许多小的程序集。
- 由于 COM 互操作而加载大量的 COM DLL。
- 在托管堆中没有同时加载程序集和 COM DLL。可能导致这一问题的一种常见情形是,在启用了“debug”配置标志的情况下对 ASP.NET 站点进行编译。这会导致每个页在其各自的程序集中进行编译,可能会产生足以引发 OOM 问题的虚拟内存空间碎片。
保留内存不需要操作系统提供物理内存。只有在 GC(垃圾收集器)提供物理内存时才会分配物理内存。如果使用非常低的物理内存来运行系统,则应该会出现 OOM 异常。检查您的物理内存是否过低的一种简单方法就是打开 Windows 任务管理器,查看“性能”选项卡上的“内存使用”区域。
图3 显示系统总共提供了 1981304 KB 内存,总内存数为 2518760 KB。当提供的内存总数接近总内存数时,系统就会耗尽可用内存。
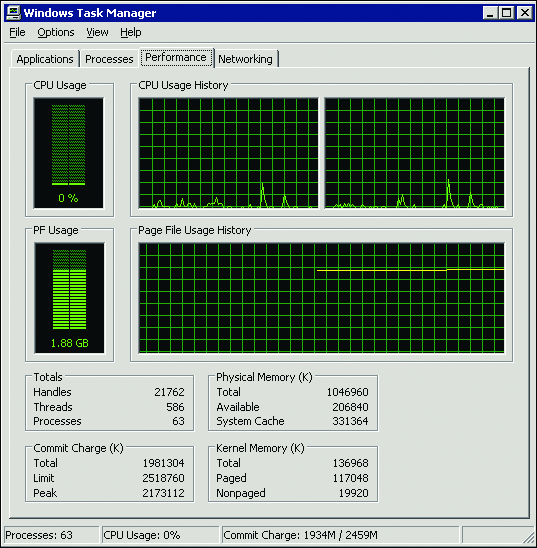
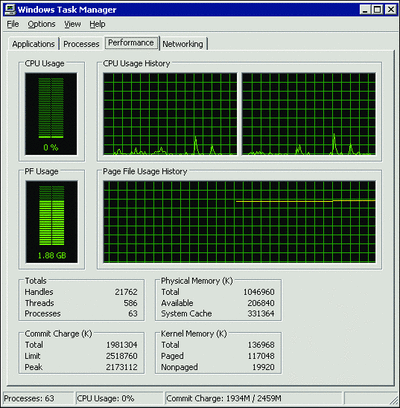
图 3任务管理器里查看可用内存 (单击该图像获得较大视图))
GC 并非一次提供整个段。而是根据需要以多个块的形式提供段。(注意,托管堆提供的字节数由 # Total committed Bytes 表示,而不是 # Bytes in all Heaps(所有堆中的字节数)。这是因为 # Bytes in all Heaps 中包含的第 0 代大小并非第 0 代中使用的实际内存,而是其预算。)
您可以使用用户模式分析器(如 CLR 分析器)了解哪些对象导致了如此高的内存使用量。但在某些情况下,运行分析器的开销让人无法接受 — 例如,当需要在生产服务器上调试问题时就会这样。在这种情况下,一种替代方法就是采取内存转储,然后使用调试器对其进行分析。那么接下来介绍一下如何使用调试器来分析托管堆。
衡量托管堆的大小
在衡量托管堆大小时,您首先需要了解的是何时进行衡量。应该在垃圾收集之前、之后还是收集过程中进行衡量?衡量堆大小的最佳时间始终是在第 2 代收集结束的时候,因为进行第 2 代收集时会收集整个堆。
要在第 2 代垃圾收集结束时查看对象,可在调试器中设置以下断点(对于服务器上的垃圾收集,只需将 WKS 替换为 SVR):
bp mscorwks!WKS::GCHeap::RestartEE "j (dwo(mscorwks!WKS::GCHeap::GcCondemnedGeneration)==2) 'kb';'g'"
现在您会在第 2 代垃圾收集结束时停止,下一步就是查看托管堆上的对象。这些对象是在垃圾收集后保留下来的对象,您希望了解它们为什么被保留下来的原因。
!dumpheap –stat 命令可对托管堆上的对象进行完整的转储。(因此,如果堆较大,!dumpheap 命令可能需要一段时间才能完成。)!dumpheap 命令生成的列表按类型和使用的内存量进行分类。这意味着您可以从最后的几行开始分析,因为这几行代表占用了大部分空间的对象。
在图4 中的示例中,字符串占用了大部分空间。如果字符串是问题的根源,那么这种问题往往容易解决。字符串的内容可反映出其来源。
您还可以在存储桶中查看字符串。例如,您可以检查大小在 150 至 200 之间的所有字符串,如图5 中所示。本例中的大量字符串都非常相似。因此,与其保留这么多字符串,不如将其共同的部分(“PendingOrder-”)和那些数字分开来保存,这样做会更有效。
我们曾经多次看到过托管堆包含重复了数千次的相同字符串的情况。结果是产生了一个字符串占用大量内存的庞大工作集。在这种情况下,使用字符串驻留往往更好。
对于其他并不像字符串这样明显的类型,您可以使用 !gcroot 来了解这些对象为何处于活动状态(请参见图6)。注意,如果对象图非常大,!gcroot 命令的执行可能需要较长时间。
除了托管堆上保留下来的对象,为您的进程提供的内存中还包含在第 0 代中分配的内存。如果允许第 0 代在下一次垃圾收集发生前增大,您还可能会观察到由于此问题而导致的内存使用量变大。这种情况在 64 位 Windows 系统上比 32 位系统更常见。!eeheap –gc SOS 命令将为您显示第 0 代的大校
如果对象保留下来会怎样?
有时,开发人员认为他们的某些对象应该处于死状态,但 GC 似乎并没有把这些对象清理掉。导致这种现象的最常见原因是:
- 对于这些对象强烈的引用仍然存在。
- 在最后一次收集对象的代时,对象还未处于死状态。
- 对象处于死状态,但还没有触发对这些对象所在的代的收集。
对于第一种和第二种情形,您可以使用 !gcroot 检查是否有强烈的引用使对象保留了下来。人们往往忽略的一种可能性就是,对象在终结器线程受阻的情况下由于尚处于终结队列中而被保留下来,受阻的原因是无法调用单线程单元 (STA) 线程,因此不会抽取消息来运行终结器(更多详细信息请参阅 support.microsoft.com/kb/828988)。您可以通过添加以下代码确定是不是这一问题:
GC.Collect(); GC.WaitForPendingFinalizers(); GC.Collect();上述代码可修复该问题,因为 WaitForPendingFinalizer 可抽取消息。不过,一旦确认是这一问题后,您应改用 Thread.Join,因为 WaitForPendingFinalizer 是非常重型的线程。
您还可以通过运行以下 SOS 命令确认是不是这一问题:
!finalizequeue查看准备终结的对象数 — 而非“可终结对象数”。当终结器受阻时,终结器线程会显示当前正在运行哪个终结器(如果有)。(请参见图7 的终结队列示例。)
了解终结器线程的一个简便方法就是查看 !threads-special 的输出。图8 所示的堆栈显示了终结器线程通常的状态 — 它正在等待一个事件指示有终结器要运行。当某个终结器受阻时,您将看到该终结器正在运行。
第三个原因不应该是问题所在。通常,除非您手动引发了垃圾收集,否则只有在 GC 认为这样做有效时才会触发收集。这意味着某个对象可能已经处于死状态,但不会立即回收其占用的内存。但当系统物理内存非常紧张时,GC 操作会变得更加积极主动。
托管堆上的碎片是否会造成问题?
在查明内存问题时,碎片是要关注的主要因素。它之所以重要是因为您需要了解托管堆上浪费了多少空间。托管堆的碎片数量由可用对象所占用的空间量来表示。您可以使用 !dumpheap 命令了解托管堆上有多少可用内存,如下所示:
0:000>!dumpheap -type Free -stat total 230 objects Statistics: MT Count TotalSize Class Name 00152b18 230 40958584 Free Total 230 objects在此例中,输出结果表明,有 230 个可用对象,总共大约 39MB。因此,此堆的碎片有 39MB。
当您尝试确定碎片是否会造成问题时,您需要了解碎片对于不同代意味着什么。对于第 0 代,碎片不构成问题,因为 GC 可以在碎片空间中进行分配。对于第 1 代和第 2 代,碎片可能会造成问题。要在第 1 代和第 2 代中使用碎片空间,GC 必须收集和提升对象以填补这些间隙。但由于第 1 代的大小不会超过一个段,因此您通常需要关注的是第 2 代。
过多的钉住通常是造成碎片太多的原因。.NET Framework 2.0 在减少由于钉住而导致碎片的问题方面做了大量改进(有关 NET Framework 2.0 中 GC 改进方面的详细信息,请参阅以下网址的博客内容:blogs.msdn.com/476750.aspx),但如果应用程序仍是过多的使用钉住,则还是会看到大量的碎片。您可以使用一个 SOS 命令 !gchandles 来查看钉住句柄的数量(请参见图9)。还可以使用 !objsize 了解哪些对象被钉住,如图10 中所示。
LOH 中的碎片是有意而为之的,因为我们没有对 LOH 进行压缩。这并不意味着 LOH 上的分配与使用 NT 堆管理器的 malloc 相同!由于 GC 的工作特点,彼此相邻的可用对象会自然地折叠成一个大的可用空间,可用于满足大型对象的分配请求。
衡量在垃圾收集上花费的时间
开发人员往往需要了解 GC 每次进行收集时所花费的时间。在软件实时情形下,该数据往往很重要,因为在这种情形下对于应用程序必须遵守的响应时间等条件有一定限制。这当然是一个重要的考虑因素,因为在垃圾收集上花费过多时间就意味着占用了 CPU 用于实际处理的时间。
了解在垃圾收集上花费的时间的最简便的方法就是查看 % Time in GC 性能计数器。该计数器在收集结束时更新,显示刚刚完成的 GC 所花费的时间与自上次 GC 结束后所经历时间的比值。如果在采样间隔内没有发生收集,则该计数器不更新,您看到的值与上次相同。由于您知道性能监视器应用程序中的采样间隔(PerfMon 中默认的采样间隔是 1 秒),您可以粗略计算出时间。
图11 给出了一些垃圾收集数据示例。其中您将看到在第二个和第三个间隔中发生了第 0 代收集。由于我们并不准确了解在这些间隔期间收集何时发生,因此这个方法并非 100% 准确。但它对于预测 GC 所花费的时间非常有用。
考虑以下示例,这对于第十一次 GC 而言是最极端的情形。假设第十次第 0 代收集在第二个间隔开始时完成,第十一次第 0 代收集在第三个间隔结束时完成。这意味着两次收集结束之间的时间大约是两个采样间隔,或者说是两秒。% Time in GC 计数器显示为 3%,因此第十一次第 0 代收集只花费了 2 秒的 3%(或 60 毫秒)。
研究高 CPU 使用
当收集发生时,CPU 使用应该较高,从而使 GC 可以尽快完成。图12 显示了收集始终会造成非常高的 CPU 使用的一个示例。% Process Time(进程时间百分比)计数器中的所有峰值直接与 % Time in GC 的变化相对应。显然,在实际中永远不会发生这种情况,因为除了 GC 使用 CPU 之外,其他进程也将使用 CPU。要确定还有哪些进程在占用 CPU 周期,您可以使用 CPU 分析器查看哪些功能占用了大多数 CPU 时间。
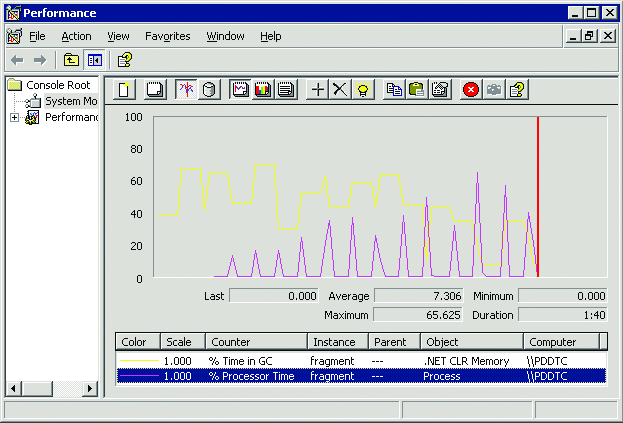
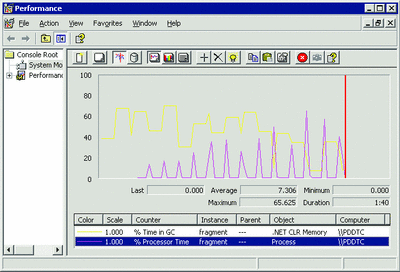
图 12当收集引起 CPU 使用之时 (单击该图像获得较大视图))
如果实际上您发现 GC 占用了太多 CPU 时间,则说明收集的发生频率过高或者收集过程所花费的时间太长。考虑当收集由分配触发时的情况。分配速率是决定收集触发频率的主要因素。
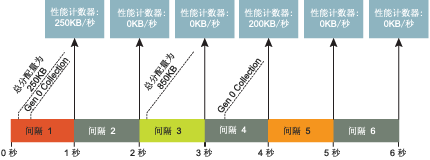
图 13当收集被分散开后产生较不准确的数据
当收集开始时,通过加上第 0 代和 LOH 中的已分配字节数对 Allocated Bytes/sec 计数器进行更新。由于该计数器以速率表示,因此您看到的实际数值是最后两个数值之间的差除以时间间隔的值。例如,图13 说明了如果采样速率为 1 秒并且收集只在经过一定间隔后才发生的情况。当收集发生时,性能计数器的更新如下:
Allocation = 850-250=600KB Alloc/Sec = 600/3=200KB/sec
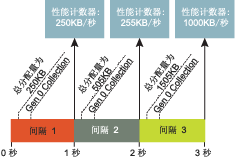
图 14数据会比较准确如果收集发生较频繁时
尽管应用程序一直在分配,但性能计数器不会反映这一情况,因为它直到下一次收集时才会更新。如果收集发生的频率再高一些,您就会获得更清楚的图像(请参见图14)。
一个常见的错误就是将分配速率用作衡量垃圾收集所花费时间的尺度 — 收集过程所花费的时间由 GC 检查的内存量决定。由于 GC 只检查保留下来的对象,因此收集时间长意味着有许多对象保留了下来。如果您遇到这种情况,可以使用我们上面讨论的技巧来确定为何有这么多对象保留了下来。